-
定义带标签的社交网络
labeled social network为 ,其中:- 特征
 , 为每个成员的特征空间的大小,
, 为每个成员的特征空间的大小, 为顶点数量。
为顶点数量。 - ,
 为
为 label空间, 为分类类别数量。
在传统机器学习算法中,我们仅仅学习从
 的映射,忽略了成员之间的社交关系。而基于图的算法中,我们可以利用 中色社交关系来提升分类准确性,在文献中这个问题被称作关系分类
的映射,忽略了成员之间的社交关系。而基于图的算法中,我们可以利用 中色社交关系来提升分类准确性,在文献中这个问题被称作关系分类relational classfication问题。传统的关系分类算法将这个问题视作无向马尔可夫网络中的一个
inference,然后使用迭代近似推理算法在给定网络结构的情况下计算标签的后验分布。这些算法融合了标签空间作为特征空间的一部分。论文
《DeepWalk: Online Learning of Social Representations》提出了DeepWalk算法,该算法基于无监督方法直接学习网络的结构特征,学得一个与标签无关的网络representation。 - 特征
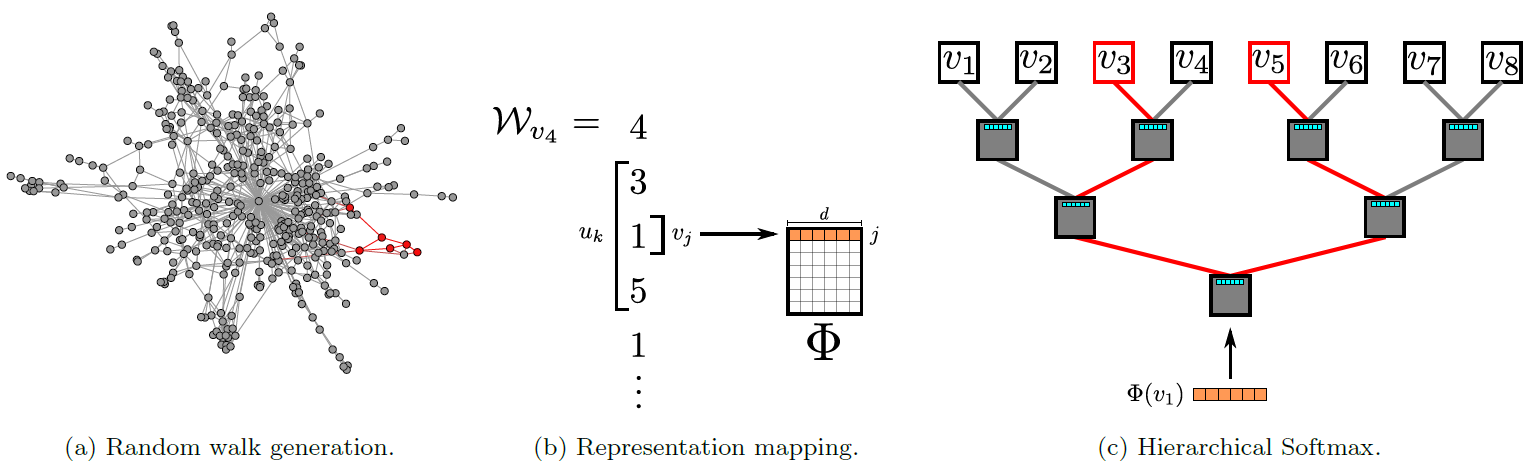
DeepWalk将图 作为输入来学习网络中顶点的潜在表达
作为输入来学习网络中顶点的潜在表达 latent representation,这种表达可以将社交关系编码到一个连续向量空间中,从而给后续模型使用。以
Karate network为例,图a给出了典型的图,图b给出了该图中所有顶点的2维潜在表达。可以看到:二者非常相似,且图b可以对应于图a的聚类。DeepWalk的目标是学习每个顶点的表达 。其中, 是一个较小的数,表示低维表达空间的维度大小。这个低维空间是分布式表达的,每个维度或者几个维度代表某种社交现象。
。其中, 是一个较小的数,表示低维表达空间的维度大小。这个低维空间是分布式表达的,每个维度或者几个维度代表某种社交现象。DeepWalk首次将深度学习技术引入到network分析中,它通过深度学习技术学习图顶点的社交表达social representation。顶点社交表达可以在低维连续空间编码社交关系social relation,从而获得网络顶点的相似性和社区成员关系community membership。这种社交表达
social representation需要满足以下特点:- 适应性
Adaptability:社交网络不断演变,新的社交关系不应该要求重新训练整个网络。 - 社区相关
Community aware:低维表示空间中的距离应该代表网络成员之间的社交相似性。 - 低维
Low dimensional:低维模型泛化效果更好,训练速度和推理速度更快。 - 连续
Continuous:连续的表示更方便建模(函数可微),且使得社区community之间的边界更平滑。
- 适应性
定义以顶点
 开始的一次随机游走序列为 ,其中:
开始的一次随机游走序列为 ,其中: 为每个序列的长度,它是算法的超参数。
为每个序列的长度,它是算法的超参数。- 是序列中的第
 个顶点,它是从 的邻居中随机选择一个顶点而生成。
个顶点,它是从 的邻居中随机选择一个顶点而生成。
如果一个图中顶点的度
degree满足幂律分布power law,则随机游走序列中顶点出现的频次也满足幂律分布。一个事实是:自然语言中单词出现的频次也满足幂律分布。由于语言模型是解决这种模式的工具,因此这些工具理论上也可以应用于
network的community structure建模。DeepWalk就是参考了神经语言模型的思想:将随机游走序列视为文本序列,从而学习顶点的潜在表达。下图给出了两个典型分布:
图
a给出了short random walk中,顶点出现频次的分布。因为随机游走序列最长的长度不超过
,因此称为short。图
b给出了英文维基百科的10万篇文章中,单词的频次分布。
语言模型的输入是语料库
 和词汇表 ,而
和词汇表 ,而 DeepWalk的输入是一组short random walk序列和图的顶点 。
。
1.1.1 算法
DeepWalk算法由两部分组成:随机游走序列生成部分、参数更新部分。随机游走序列生成:随机游走序列生成器从图 中均匀随机采样一个顶点
作为序列 的起点,然后生成器从上一个访问顶点的邻居节点中均匀随机采样一个顶点作为序列的下一个点。- 论文中将序列的长度设置为最长为 ,但是论文也提到:理论上序列的长度不一定是固定的,没有任何限制。
- 随机游走可以选择随机重启,即以一定的概率回到起始点。但是论文的实验结果显示:随机重启并没有任何优势。
- 论文中将序列的长度设置为最长为
- 参数更新部分:
对于每一个顶点 ,
DeepWalk随机生成以 为起点的 条随机游走序列。每条随机游走序列都是独立采样的,它们都是以顶点 为起点。DeepWalk算法:输入:
- 图
- 窗口尺寸

- 顶点的
embedding size - 游走序列长度
输出:所有顶点的
representation矩阵算法步骤:
从
 中随机采样来初始化
中随机采样来初始化 从
构建一颗二叉树 binary tree迭代:
 ,迭代步骤:
,迭代步骤:随机混洗顶点: 。
每次遍历的开始,随机混洗顶点。但是这一步并不是严格要求的,但是它可以加快随机梯度下降的收敛速度。
-
- 利用随机游走生成器生成随机游走序列:

- 采用
SkipGram算法来更新顶点的表达:
- 利用随机游走生成器生成随机游走序列:
DeepWalk算法有两层循环:- 外层循环指定应该在每个顶点开始随机游走的轮次。
- 内存循环遍历图 中的所有顶点。
对于每个随机游走序列中的顶点
,我们基于 SkipGram的思想最大化 邻居结点的概率。SkigGram算法:输入:
- 顶点的
representation矩阵
- 随机游走序列
- 窗口大小
- 顶点的
输出:更新后的顶点 矩阵
算法步骤:
对随机游走序列
 的每个顶点:迭代,迭代步骤:
的每个顶点:迭代,迭代步骤:对
 窗口内的所有邻居顶点 ,执行:
窗口内的所有邻居顶点 ,执行:
其中 表示
 是顶点 邻居结点的概率。
是顶点 邻居结点的概率。
由于类别标签数量等于
,这可能是百万或者数十亿,因此每次迭代过程中计算 。为了加快训练速度,通常采用 Hierarchical Softmax。这也是前面为什么要对顶点建立二叉树 的原因。
的原因。假设到达顶点 经过的二叉树中间结点依次为
 ,其中 ,则有:
,其中 ,则有:
而 可以直接用二分类建模,因此计算
 的整体复杂度从 降低到
的整体复杂度从 降低到  。
。如果对更频繁出现的顶点赋予更短的路径,则得到霍夫曼编码树,这可以进一步降低计算代价。
1.1.1 训练和优化
DeepWalk算法的参数为 和 ,参数采用随机梯度下降法来优化。其中学习率 初始值为
,参数采用随机梯度下降法来优化。其中学习率 初始值为 0.025,然后随着已见过的顶点数量线性衰减。DeepWalk算法有两个理想的优点:支持增量学习,因此是一种在线学习算法。
当图
发生变化时,我们可以在发生变化的局部区域用随机游走生成器生成新的随机游走序列来更新模型,从而可以用较小的代价来增量更新模型,无需重新计算整个图 。容易并行化,不同的随机游走生成器可以并行探索图
的不同部分。此外,在训练时我们可以使用异步随机梯度下降
ASGD方法。在ASGD中我们访问共享参数时不需要加锁,这可以实现更快的收敛速度(见图a)并且没有预测性能的损失(见图b)。之所以如此时因为:社交网络随机游走序列的顶点频次分布和
NLP单词频次分布都遵循幂律分布,因此会出现长尾效应,大多数顶点出现次数较少。这使得对 的更新是稀疏的,即:同时对同一个顶点进行更新的概率很低。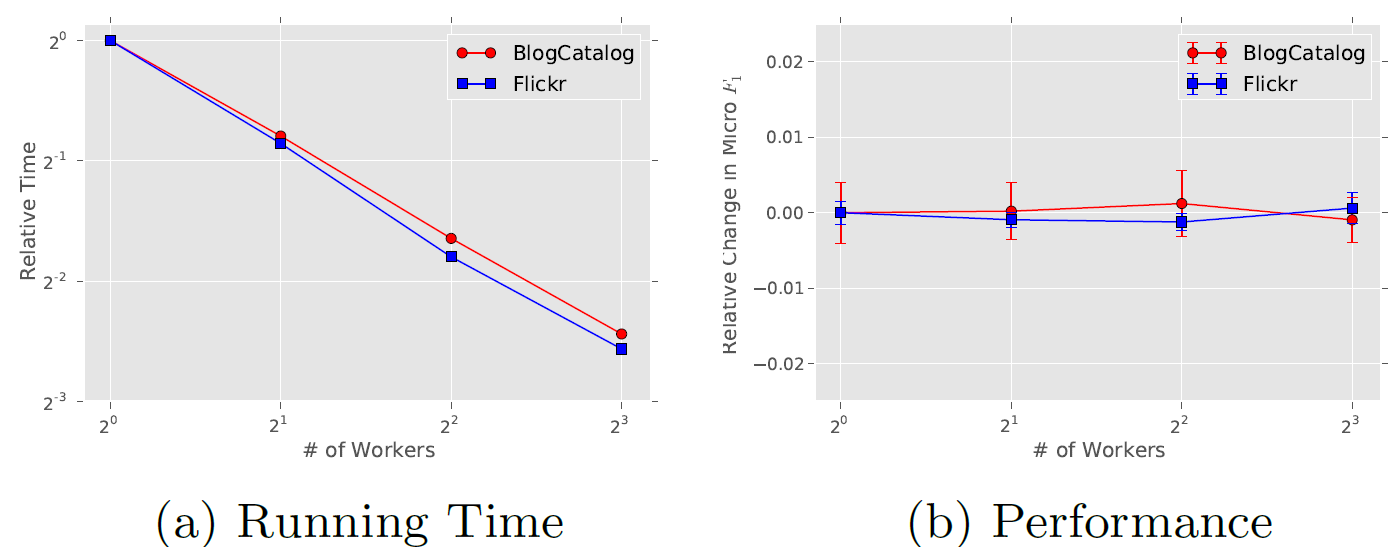
DeepWalk可以挖掘图 的局部结构,但是无法挖掘图 的整体结构。DeepWalk算法还有两个变种模式:流式计算模式:在不知道图 整体信息的情况下实现
DeepWalk。在这种模式下,从图中得到的一小段随机游走序列直接传给学习器来更新模型。此时算法需要进行以下修改:- 学习率
 不再是衰减的,而是固定为一个小的常数。这使得算法的训练需要更长的时间。
不再是衰减的,而是固定为一个小的常数。这使得算法的训练需要更长的时间。 - 不必再建立二叉树 。但是如果顶点数量 已知,则也可以建立二叉树。
- 学习率
非随机游走模式:在某些图中,有些路径的产生并不是随机的,如:用户浏览网页元素的路径。对于这些图,我们可以直接使用用户产生的路径而不是随机生成的路径来建模。
通过这种方式,我们不仅可以建模网络结构,还可以建模这些路径的热度。
1.2 实验
数据集:
BlogCatalog数据集:由博客作者提供的社交关系网络。标签代表作者提供的主题类别。YouTube数据集:YouTube网站用户之间的社交网络。标签代表用户的视频兴趣组,如“动漫、摔跤”。
对比模型:
谱聚类
SpectralClustering:从图 的 normalized graph Laplacian矩阵 中计算到的 个最小的特征向量,构成图的表达。
个最小的特征向量,构成图的表达。EdgeCluster:基于k-means聚类算法对图 的邻接矩阵进行聚类。事实证明它的性能可以和Modularity相比,并且可以扩展到那些超大规模的图,这些图太大而难以执行谱分解。wvRN:weighted-vote Relational Neighbor是一个关系分类器relational classi er。给定顶点 的邻居 ,wvRN通过邻居结点的加权平均来预估 :
:其中
 为归一化系数。
为归一化系数。该方法在真实网络中表现良好,并被推荐作为一个优秀的关系分类基准。
Majority:选择训练集中出现次数最多的标签作为预测结果(所有样本都预测成一个值)。
评估指标:对于多标签分类问题
multilabel classi cation,我们采用Macro-F1和Micro-F1作为评估指标。Macro-F1:根据整体的混淆矩阵计算得到的 值。micro-F1:先根据每个类别的混淆矩阵计算得到各自的 值,然后对所有 值取平均。
值,然后对所有 值取平均。
另外我们采用模型提取的特征训练
one-vs-rest逻辑回归分类器,根据该分类器来评估结果。
1.2.1 模型结果
实验条件:
- 随机采样一个比例为
 的带标签顶点作为训练数据,剩下顶点作为测试数据。
的带标签顶点作为训练数据,剩下顶点作为测试数据。 - 所有流程执行
10次并汇报平均性能。 - 对于
DeepWalk,我们汇报 的结果;对于SpectralClustring,Modularity,EdgeCluster,我们汇报 的结果。
的结果。
- 随机采样一个比例为
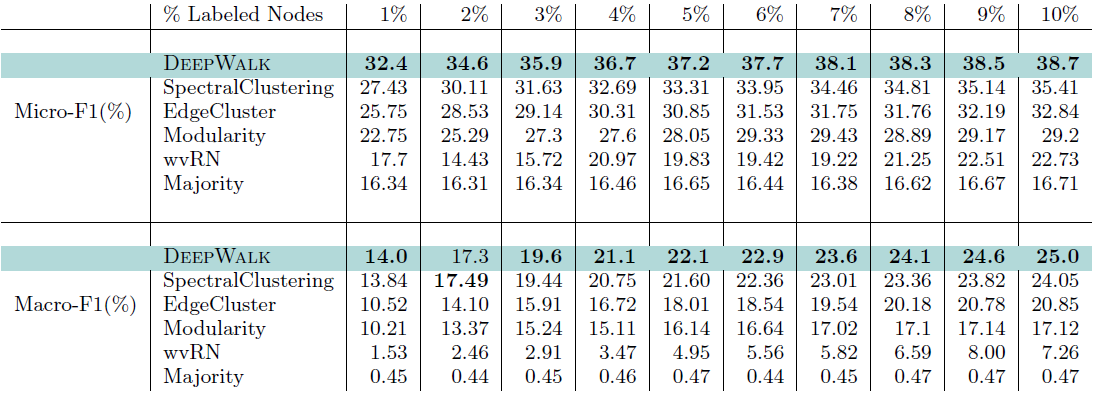
BlogCatalog数据集:我们评估 的结果。结果如下表,粗体表示每一列最佳结果。结论:
DeepWalk性能始终优于EdgeCluster,Modularity,wvRN。事实上当
DeepWalk仅仅给出20%标记样本来训练的情况下,模型效果优于其它模型90%的标记样本作为训练集。虽然
SpectralClustering方法更具有竞争力,但是当数据稀疏时DeepWalk效果最好:- 对于
Macro-F1指标, 时
时 DeepWalk效果更好。 - 对于
Micro-F1指标, 时DeepWalk效果更好。
- 对于
- 当仅标记图中的一小部分时,
DeepWalk效果最好。因此后面实验我们更关注稀疏标记图sparsely labeled graph。
数据集:我们评估 的结果。结果如下表,粗体表示每一列最佳结果。结论与前面的实验一致。
- 在
Micro-F1指标上,DeepWalk比其它基准至少有3%的绝对提升。 - 在
Micro-F1指标上,DeepWalk只需要3%的标记数据就可以打败其它方法10%的标记数据,因此DeepWalk的标记样本需求量比基准方法少60%。 - 在
Macro-F1指标上,DeepWalk性能接近SpectralClustring,击败了所有其它方法。
- 在
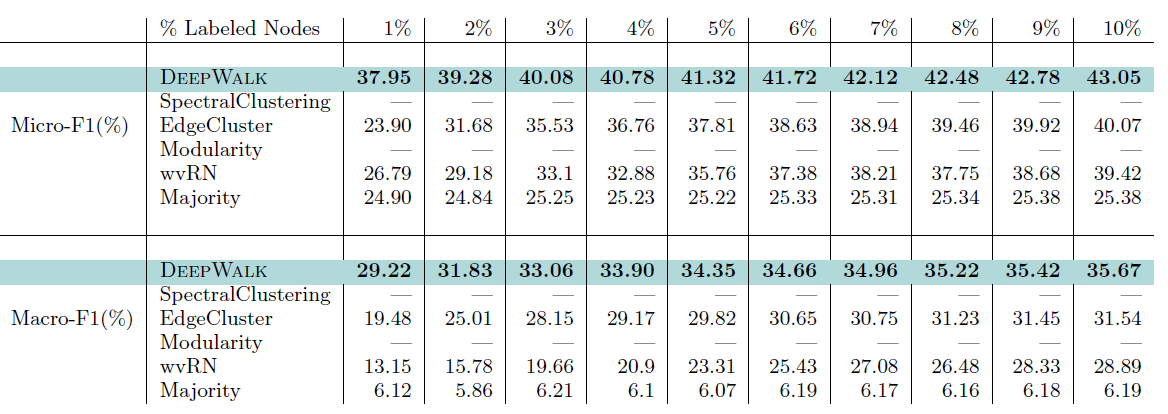
YouTube数据集:我们评估 的结果。结果如下表,粗体表示每一列最佳结果。由于
YouTube规模比前面两个数据集大得多,因此我们无法运行两种基准方法SpecutralClustering,Modularity。DeepWalk性能远超EdgeCluster基准方法:- 当标记数据只有
1%时,DeepWalk在Micro-F1指标上相对EdgeCluster有14%的绝对提升,在Macro-F1指标上相对EdgeCluster有10%的绝对提升。 - 当标记数据增长到
10%时,DeepWalk提升幅度有所下降。DeepWalk在Micro-F1指标上相对EdgeCluster有3%的绝对提升,在Macro-F1指标上相对EdgeCluster有4%的绝对提升。
- 当标记数据只有
DeepWalk能扩展到大规模网络,并且在稀疏标记环境中表现出色。
1.2.2 超参数效果
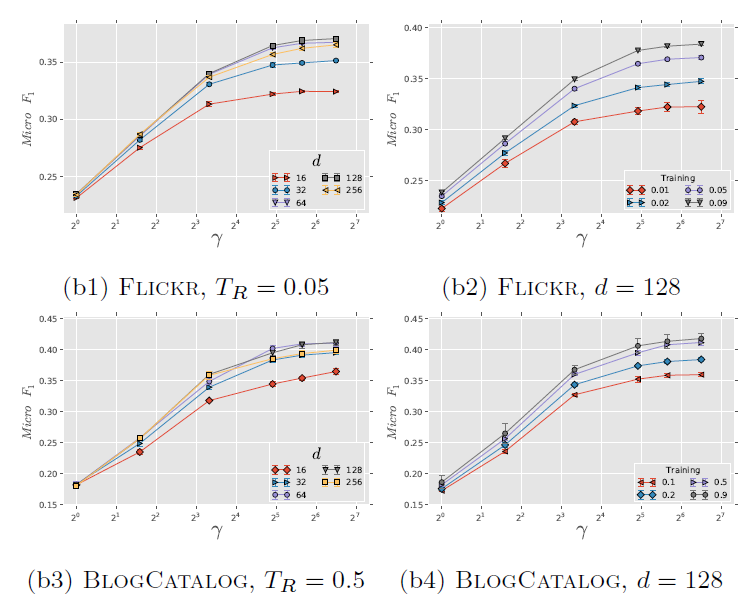
为评估超参数的影响,论文在
Flickr和BlogCatalog数据集上进行实验。我们固定窗口大小 和游走长度 。
。考察不同 的效果:
图
a1和 图a3考察不同 和不同 的效果。Flickr和BlogCatalog数据集上模型的表现一致:模型最佳尺寸 取决于训练样本的数量。注意:
Flickr的1%训练样本和BlogCatalog的10%训练样本,模型的表现差不多。图
a2和图a4考察不同 和不同 的效果。
的效果。在不同 取值上,模型性能对于不同
的变化比较稳定。- 从 开始继续提高 时模型的效果提升不大,因此 几乎取得最好效果。继续提升效果,计算代价上升而收益不明显。
- 从 开始继续提高
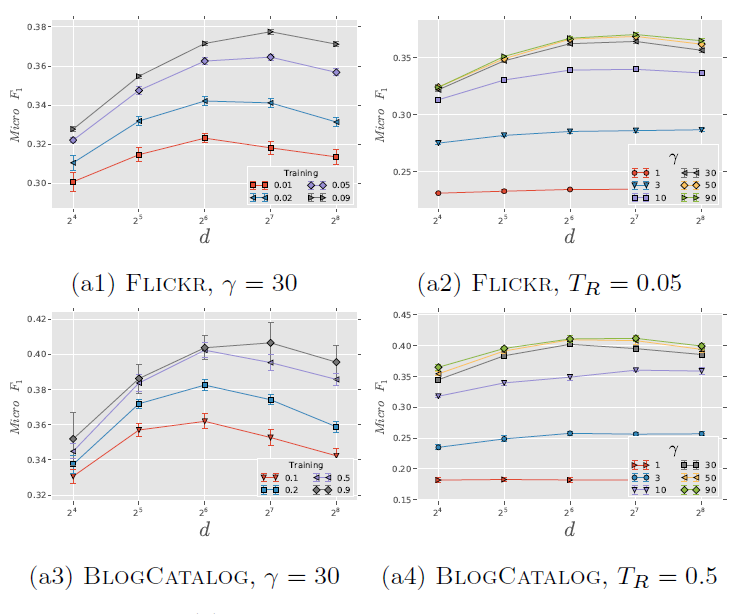
考察不同 的影响。图
b1和b3考察不同 的效果,图 b2和b4考察了不同 的效果。实验结果表明,它们的表现比较一致:增加
时开始可能有巨大提升,但是当 时提升效果显著下降。这些结果表明:仅需要少量的随机游走,我们就可以学习有意义的顶点潜在表示。