
-
论文
“Deep Crossing: Web-Scale Modeling without Manually Crafted Combinatorial Features”提出了Deep Crossing模型,该模型利用深度神经网络来自动组合特征从而生成高阶特征。 虽然
Deep Crossing模型能够自动组合原始特征,但是收集原始数据并提取原始特征仍需要用户的大量精力。
在搜索广告
sponsored search任务中,我们有大量的原始特征,每个原始特征都用一个向量表示。论文考察的原始特征包括:用户
Query:用户的搜索文本。广告主竞价
Keyword:广告主的竞价关键词。广告
Title:广告的标题文本。对于
Query,Keyword,Title等文本特征,论文通过将文本字符串转换为字符级的3-gram的形式,得到一个 49292 维的向量。其中 49292 为3-gram词典大小。MatchType:广告主指定的关键词匹配类型,分为exact,phrase,broad,contextual四种。论文将其转换为一个 4 维的
one-hot向量。CampaignID:营销campaign的ID。
用到的特征如下图所示:
DeepCrossing模型的输入是原始特征,模型有四种类型的Layer:-
假设原始特征
one-hot向量为 ,
,field i在向量中的起始位置为 、终止位置为 (包含)。则
(包含)。则 embedding层的输出为:其中
 为参数, 为第
为参数, 为第  个
个 embedding的维度。通常有 ,这使得
embedding之后的维度大大小于原始特征维度。对于某些维度较小的原始特征(如:维度小于 256),无需进行
embedding层,而是直接输入到Stacking Layer层。如图中的Feature #2。这是在模型大小和信息保留程度之间的折衷:
- 完全保留信息(原始输入),则可能使得模型过大
- 全部使用
embedding,则可能信息丢失太多
Stacking Layer:所有embedding特征和部分原始特征拼接成一个向量:
其中 表示特征拼接,
 为原始特征的数量, 为
为原始特征的数量, 为 embedding向量。如果是直接输入的原始特征,则 表示该原始特征的
表示该原始特征的 one-hot向量。Residual Unit Layer:基于残差单元Residual Unit构建的残差层,其输出为:其中
 为残差单元:
为残差单元:注意:在一个
DeepCrossing网络中可以有多个残差层。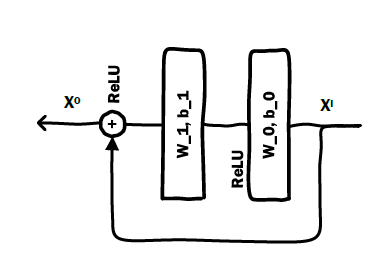
-
模型的损失函数为负的
Logloss:
DSSM模型也可以认为是执行了特征交叉。DSSM模型有两路输入:Query、Ad Text。模型分别抽取特征,最后计算二者的cosin距离,该距离就代表了二者的特征交叉。与
DeepCrossing相比, 的特征交叉发生的时间比较靠后。从效果上讲,DeepCrossing的特征交叉发生时间靠前的效果更好。
实验结果表明:是否包含某些原始特征对模型效果影响较大。
下图比较了引入不同特征的情况下,每个训练
epoch结束时的验证集logloss。该logloss除以All_features模型的最低logloss来归一化。All_features:使用所有的特征。Without_Q_K_T:不使用counting特征,且不使用Query,Keyword,Title等文本特征。Only_Q_K:仅使用Query,Keyword特征。Without_position:不使用counting特征,且不使用广告的位置信息。
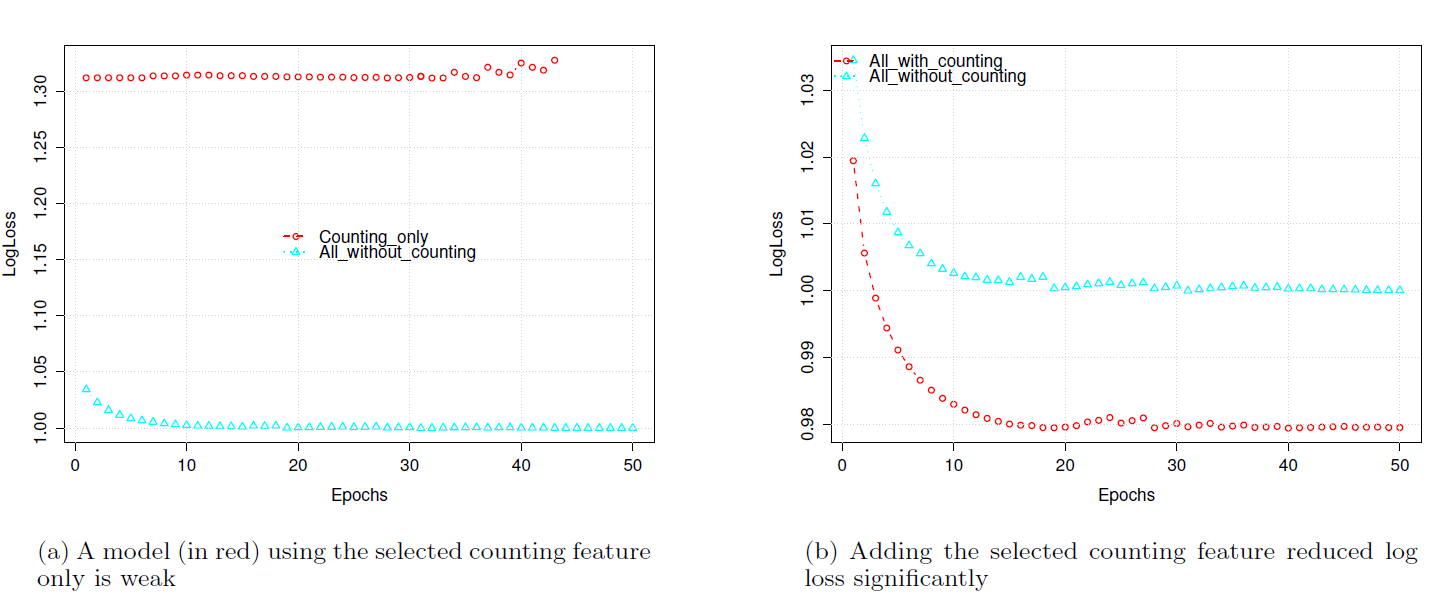
下图比较了是否包含
counting特征的效果。logloss除以All_without_counting模型的最低logloss来归一化。All_with_counting:使用包含counting在内的所有特征All_without_counting:使用剔除counting后的所有特征。
DeepCrossing和DSSM的比较:评估指标为AUC,其中以DSSM的结果作为基准来归一化。text_cp1_tn_s、text_cp1_tn_b为论文构造的两个训练集,text_cp1_tn_s1.94亿样本,训练集text_cp1_tn_b29.3亿样本。评估在对应的测试集上进行:验证集 0.49亿样本,测试集 0.45亿样本。

