
-
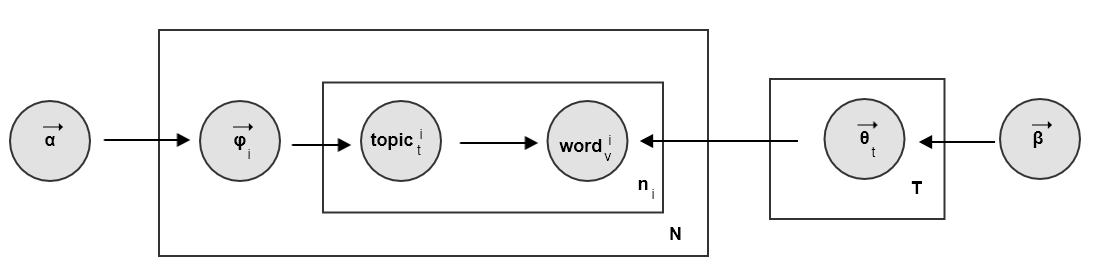
- 参数 为文档
 的主题分布(离散型的),其中 。该分布也是一个随机变量,服从分布
的主题分布(离散型的),其中 。该分布也是一个随机变量,服从分布  (连续型的)。
(连续型的)。 - 参数 为主题
 的单词分布(离散型的),其中 。该分布也是一个随机变量,服从分布
的单词分布(离散型的),其中 。该分布也是一个随机变量,服从分布  (连续型的)。
(连续型的)。
因此
LDA模型是pLSA模型的贝叶斯版本。 - 参数 为文档
例:在
pLSA模型中,给定一篇文档,假设:- 主题分布为
{教育:0.5,经济:0.3,交通:0.2},它就是 。 - 主题
教育下的主题词分布为{大学:0.5,老师:0.2,课程:0.3},它就是 。
。
在
LDA中:给定一篇文档,主题分布 不再固定 。可能为
{教育:0.5,经济:0.3,交通:0.2},也可能为{教育:0.3,经济:0.5,交通:0.2},也可能为{教育:0.1,经济:0.8,交通:0.1}。但是它并不是没有规律的,而是服从一个分布
 。即:主题分布取某种分布的概率可能较大,取另一些分布的概率可能较小。
。即:主题分布取某种分布的概率可能较大,取另一些分布的概率可能较小。主题下的主题词分布也不再固定。可能为
{大学:0.5,老师:0.2,课程:0.3},也可能为{大学:0.8,老师:0.1,课程:0.1}。但是它并不是没有规律,而是服从一个分布 。即:主题词分布取某种分布的概率可能较大,取另一些分布的概率可能较小。
- 主题分布为
LDA模型的文档生成规则:- 根据参数为
 的狄利克雷分布随机采样,对每个话题 生成一个单词分布
的狄利克雷分布随机采样,对每个话题 生成一个单词分布  。每个话题采样一次,一共采样 次。
。每个话题采样一次,一共采样 次。 - 根据参数为
 的狄利克雷分布随机采样,生成文档 的一个话题分布
的狄利克雷分布随机采样,生成文档 的一个话题分布  。每篇文档采样一次。
。每篇文档采样一次。 - 根据话题分布 来随机挑选一个话题。然后在话题 中,根据单词分布 来随机挑选一个单词。
- 重复执行
挑选话题--> 挑选单词 次,则得到一篇包含 个单词
次,则得到一篇包含 个单词  的文档,记作 。其中:
的文档,记作 。其中:  , 表示文档的第
, 表示文档的第  个单词为 。
个单词为 。
- 根据参数为
对于包含
 篇文档的数据集 ,假设所有文档都是如此生成。则数据集
篇文档的数据集 ,假设所有文档都是如此生成。则数据集  的生成规则:
的生成规则:以概率 选中第
 篇文档。
篇文档。根据参数为 的狄利克雷分布随机采样,对每个话题
 生成一个单词分布 。每个话题采样一次,一共采样
生成一个单词分布 。每个话题采样一次,一共采样  次。
次。生成文档 :
- 根据参数为 的狄利克雷分布随机采样,生成文档 的一个话题分布
 。每篇文档采样一次。
。每篇文档采样一次。 - 在文档 中,根据话题分布
 来随机挑选一个话题。然后在话题 中,根据单词分布
来随机挑选一个话题。然后在话题 中,根据单词分布  来随机挑选一个单词。
来随机挑选一个单词。 - 重复执行
挑选话题--> 挑选单词次,则得到一篇包含 个单词 的文档,记作
个单词 的文档,记作  。
。
- 根据参数为
- 重复执行上述文档生成规则 次,即得到 篇文档组成的文档集合 。
由于两次随机采样,导致
LDA模型的解会呈现一定程度的随机性。所谓随机性,就是:当多次运行LDA算法,获得解可能会各不相同当采样的样本越稀疏,则采样的方差越大,则
LDA的解的方差越大。- 文档数量越少,则文档的话题分布的采样越稀疏。
- 文档中的单词越少,则话题的单词分布的采样越稀疏。
由于使用词袋模型,
LDA生成文档的过程可以分解为两个过程: :该过程表示,在生成第 篇文档 的时候,先从
:该过程表示,在生成第 篇文档 的时候,先从文档-主题分布 中生成 个主题。其中:
- 表示文档 的第 个单词由主题 生成。
- 表示文档 一共有 个单词。
- 表示文档
 :该过程表示,在已知主题为 的条件下,从
:该过程表示,在已知主题为 的条件下,从主题-单词分布 生成 个单词。
生成 个单词。其中:
 表示由主题 生成的的第 个单词为 。
表示由主题 生成的的第 个单词为 。 为由 生成的单词的数量。
为由 生成的单词的数量。
3.2.1 主题生成过程
主题生成过程用于生成第 篇文档
中每个位置的单词对应的主题。:对应一个狄里克雷分布
 :对应一个多项式分布
:对应一个多项式分布该过程整体对应一个 共轭结构:
合并文档
中的同一个主题。设 表示文档 中,主题 出现的次数。则有:
则有:
其中
 表示文档 中,各主题出现的次数。
表示文档 中,各主题出现的次数。由于语料库中
篇文档的主题生成相互独立,则得到整个语料库的主题生成概率:.
3.2.2 单词生成过程
合并主题 生成的同一个单词。设
 表示中主题 生成的单词中,
表示中主题 生成的单词中, 出现的次数。则有:
出现的次数。则有:则有:

其中 表示由主题
生成的单词的词频。考虑数据集 中的所有主题,由于不同主题之间相互独立,则有:

这里是按照主题来划分单词,如果按照位置来划分单词,则等价于:
注意:这里
 的意义发生了变化:
的意义发生了变化:- 对于前者, 表示由主题 生成的第 个单词。
- 对于后者,
 表示文档 中的第 个单词。
表示文档 中的第 个单词。
- 对于前者, 表示由主题
3.2.3 联合概率
数据集
的联合概率分布为:其中:
- 表示文档 中,各主题出现的次数。
 表示主题 生成的单词中,各单词出现的次数。
表示主题 生成的单词中,各单词出现的次数。
3.2.4 后验概率
若已知文档
中的主题 ,则有:
则有: 。这说明参数
 的后验分布也是狄里克雷分布。
的后验分布也是狄里克雷分布。若已知主题 及其生成的单词
 则有:
则有:则有: 。这说明参数
的后验分布也是狄里克雷分布。
LDA的求解有两种办法:变分推断法、吉布斯采样法。
3.3.1 吉布斯采样
对于数据集 :
- 其所有的单词
 是观测的已知数据,记作 。
是观测的已知数据,记作 。 - 这些单词对应的主题
 是未观测数据,记作 。
是未观测数据,记作 。
需要求解的分布是:
 。其中: 表示文档 的第 个单词为 , 表示文档 的第 个单词由主题 生成。
。其中: 表示文档 的第 个单词为 , 表示文档 的第 个单词由主题 生成。- 其所有的单词
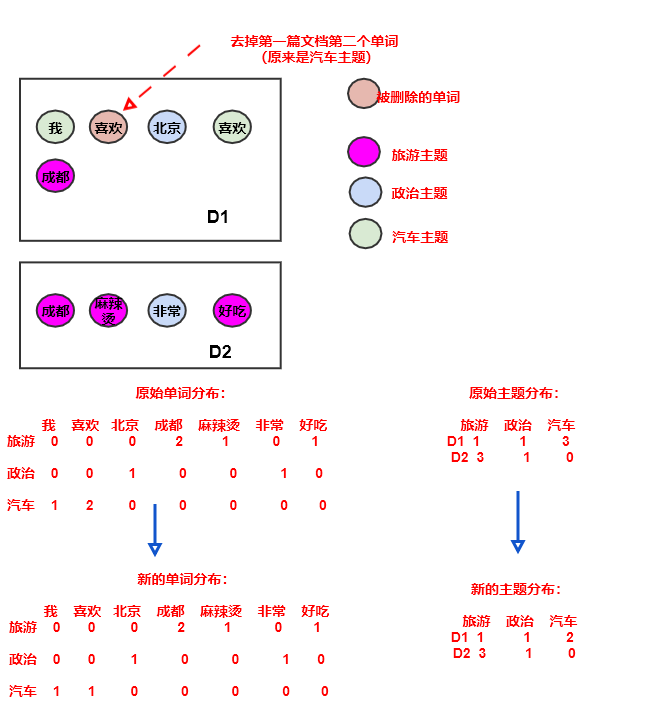
定义 为:去掉
的第 个单词背后的那个生成主题(注:只是对其频数减一):
定义 为:去掉
的第 个单词:
根据吉布斯采样的要求,需要得到条件分布:
根据条件概率有:

则有:
对于文档
的第 个位置,单词  和对应的主题 仅仅涉及到如下的两个
和对应的主题 仅仅涉及到如下的两个狄里克雷-多项式共轭结构:- 文档 的主题分布
- 已知主题为
 的情况下单词的分布
的情况下单词的分布
对于这两个共轭结构,去掉文档
的第 个位置的主题和单词时:先验分布(狄里克雷分布):保持不变。
文档
的主题分布:主题 频数减少一次,但是该分布仍然是多项式分布。其它  个文档的主题分布完全不受影响。因此有:
个文档的主题分布完全不受影响。因此有:主题
 的单词分布:单词 频数减少一次,但是该分布仍然是多项式分布。其它
的单词分布:单词 频数减少一次,但是该分布仍然是多项式分布。其它  个主题的单词分布完全不受影响。因此有:
个主题的单词分布完全不受影响。因此有:根据主题分布和单词分布有:

其中:
- 表示去掉文档 的第 个位置的单词和主题之后,第 篇文档中各主题出现的次数。
- 表示去掉文档 的第 个位置的单词和主题之后,数据集 中,由主题 生成的单词中各单词出现的次数。
- 表示去掉文档
- 文档
考虑 。记
 ,则有:
,则有:考虑到主题生成过程和单词生成过程是独立的,则有:

考虑到文档 的第
个位置的单词背后的主题选择过程和其它文档、以及本文档内其它位置的主题选择是相互独立的,则有:考虑到文档
的第 个位置的单词选择过程和其它文档、以及本文档内其它位置的单词选择是相互独立的,则有:
则有:
根据狄里克雷分布的性质有:

则有:
其中:
 为文档 的第 个位置的单词背后的主题在主题表的编号; 为文档 的第 个位置的单词在词汇表中的编号。
为文档 的第 个位置的单词背后的主题在主题表的编号; 为文档 的第 个位置的单词在词汇表中的编号。根据上面的推导,得到吉布斯采样的公式(
 ):
):- 第一项刻画了:文档 中,第 个位置的单词背后的主题占该文档所有主题的比例(经过 先验频数调整)。
- 第二项刻画了:在数据集 中,主题
 中,单词 出现的比例(经过 先验频数调整)。
中,单词 出现的比例(经过 先验频数调整)。 - 它整体刻画了:文档 中第 个位置的单词为 ,且由主题 生成的可能性。
- 第一项刻画了:文档
令:
- 为数据集中所有主题的先验频数之和
 为数据集中所有单词的先验频数之和
为数据集中所有单词的先验频数之和- 表示去掉文档 位置 的主题之后,文档
 剩下的主题总数。它刚好等于 ,其中
剩下的主题总数。它刚好等于 ,其中  表示文档 中单词总数,也等于该文档中的主题总数。
表示文档 中单词总数,也等于该文档中的主题总数。  表示:数据集 中属于主题
表示:数据集 中属于主题  的单词总数。
的单词总数。- 表示去掉文档 位置 的单词之后,数据集 中属于主题 的单词总数,则它等于
 。
。
则有:
考虑到对于文档
来讲, 是固定的常数,因此有:
事实上,上述推导忽略了一个核心假设:考虑到采取词袋假设,
LDA假设同一篇文档中同一个单词(如:喜欢)都由同一个主题生成。定义 为:已知所有单词,以及去掉文档
中单词 出现的所有位置(对某个单词,如喜欢,可能在文档中出现很多次)背后的主题的条件下,单词 由主题 生成的概率。则有:

其中:
表示:去掉单词
出现的所有位置背后的主题之后,文档 剩余的主题中,属于主题 的总频数。则根据定义有:其中
表示文档 中单词总数,也等于该文档中的主题总数; 为文档 中单词 出现的次数。
为文档 中单词 出现的次数。表示:去掉文档
 单词 出现的所有位置背后的主题之后,数据集 中由主题 生成的单词 总数。则根据定义有:
单词 出现的所有位置背后的主题之后,数据集 中由主题 生成的单词 总数。则根据定义有:其中
表示数据集 中属于主题 的单词总数。
这称作基于单词的采样:每个单词采样一次,无论该单词在文档中出现几次。这可以确保同一个文档中,相同的单词由同一个主题生成。
前面的采样方式称作基于位置的采样:每个位置采样一次。这种方式中,同一个文档的同一个单词如果出现在不同位置则其主题很可能会不同。
3.3.2 模型训练
定义
文档-主题计数矩阵 为:
为:其中第
行代表文档 的主题计数。定义
主题-单词计数矩阵 为:
为:其中第
行代表 主题 的单词计数LDA训练的吉布斯采样算法(基于位置的采样)输入:
- 单词词典

- 超参数
- 主题数量
- 单词词典
输出:
文档-主题分布 的估计量
主题-单词分布
的估计量
算法步骤:
设置全局变量:
- 表示文档 中,主题 的计数。它就是
 ,也就是 的第 行第 列。
,也就是 的第 行第 列。  表示主题 中,单词 的计数。它就是 ,也就是 的第 行第
表示主题 中,单词 的计数。它就是 ,也就是 的第 行第  列。
列。- 表示各文档 中,主题的总计数。它也等于该文档的单词总数,也就是文档长度,也就是 的第 行求和。
- 表示单主题 中,单词的总计数。它也就是 的第 行求和。
- 表示文档
随机初始化:
对全局变量初始化为 0 。
遍历文档:
对文档
中的每一个位置 ,其中 为文档 的长度:- 随机初始化每个位置的单词对应的主题:

- 增加“文档-主题”计数:
- 增加“文档-主题”总数:

- 增加“主题-单词”计数:
- 增加“主题-单词”总数:

- 随机初始化每个位置的单词对应的主题:
迭代下面的步骤,直到马尔科夫链收敛:
遍历文档:
对文档
中的每一个位置 ,其中 为文档 的长度:删除该位置的主题计数,设
 :
:根据下面的公式,重新采样得到该单词的新主题
 :
:记新的主题在主题表中的编号为
 ,则增加该单词的新的主题计数:
,则增加该单词的新的主题计数:
如果马尔科夫链收敛,则根据下列公式生成
文档-主题分布 的估计,以及
的估计,以及主题-单词分布 的估计:
如果使用基于单词的采样,则训练过程需要调整为针对单词训练,而不是针对位置训练:
对文档 中的每一个词汇
 ,其中 为出现在文档 的词汇构成的词汇表的大小。:
,其中 为出现在文档 的词汇构成的词汇表的大小。:- 随机初始化每个词汇对应的主题:
- 增加“文档-主题”计数:

- 增加“文档-主题”总数:
- 增加“主题-单词”计数:

- 增加“主题-单词”总数:
其中
 表示文档 中单词 出现的次数。
表示文档 中单词 出现的次数。采样公式:
主题更新公式:

通常训练时对 和
 进行批量更新:每采样完一篇文档或者多篇文档时才进行更新,并不需要每次都更新。
进行批量更新:每采样完一篇文档或者多篇文档时才进行更新,并不需要每次都更新。- 每次更新会带来频繁的更新需求,这会带来工程实现上的难题。如分布式训练中参数存放在参数服务器,频繁更新会带来大量的网络通信,网络延时大幅增加。
- 每次更新会使得后一个位置(或者后一个单词)的采样依赖于前一个采样,因为前一个采样会改变文档的主题分布。这使得采样难以并行化进行,训练速度缓慢。
这使得训练时隐含一个假设:在同一篇文档的同一次迭代期间, 计数、
主题-单词矩阵保持不变。即:参数延迟更新。
3.3.3 模型推断
理论上可以通过最大似然估计来推断新的文档 的主题分布。设新文档有
个单词,分别为 。 假设这些单词背后的主题分别为  。则有:
。则有:由于单词的生成是独立的,且主题的单词分布是已经求得的,因此有:

由于主题的选择是独立的,但是文档的主题分布未知,该主题分布是从狄里克雷分布采样。因此有:
其中
 为文档中主题 的频数。
为文档中主题 的频数。因此有:

由于 取值空间有
个,则新文档中可能的主题组合有 种,因此最大似然  计算量太大而无法进行。
计算量太大而无法进行。有三种推断新文档主题分布的策略。假设训练文档集合为 ,待推断的文档集合为
 ,二者的合集为 。
,二者的合集为 。完全训练:
- 首先单独训练
 到模型收敛。
到模型收敛。 - 然后加入 ,并随机初始化新文档的主题,继续训练模型到收敛。
这种做法相当于用
 的训练结果为 的主题进行初始化( 的部分仍然保持随机初始化)。其推理的准确性较高,但是计算成本非常高。
的训练结果为 的主题进行初始化( 的部分仍然保持随机初始化)。其推理的准确性较高,但是计算成本非常高。- 首先单独训练
固定主题:
- 首先单独训练 到模型收敛。
- 然后加入 ,并随机初始化新文档的主题,继续训练模型到收敛。训练过程中固定 的主题。
这种做法只需要在第二轮训练中更新
的主题。固定单词:
- 首先单独训练 到模型收敛。

