
-
通常识别顶点的角色需要利用顶点的特征或者边的特征,但是仅仅依靠网络结构来识别顶点角色,这更有挑战性。此时,顶点的角色仅仅取决于顶点之间的链接。
确定顶点结构角色的常用方法是基于距离的方法或者基于递归的方法:
- 基于距离的方法:根据每个顶点的邻域信息(如邻域大小,邻域形状)来计算每对顶点之间的距离(邻域越相似则距离越小),然后通过聚类、规则匹配等方式来确定顶点的等效类别。
- 基于递归的方法:构造基于邻域的递归,然后不停迭代直到收敛,并采用最终迭代的结果来确定顶点的等效类别。如
Weisfeiler-Lehman算法。
最近一些网络顶点的
embedding学习方法非常成功,这些方法认为相邻的顶点具有相似的representation。因此具有结构相似、但是相距很远的两个顶点将不会有相似的embedding。如下图所示,顶点 和顶点 扮演相似的角色(具有相似的局部结构),但是它们在网络上相距甚远。由于它们的邻域不相交,因此一些最新的
扮演相似的角色(具有相似的局部结构),但是它们在网络上相距甚远。由于它们的邻域不相交,因此一些最新的embedding方法无法捕获它们的结构相似性。下图中,顶点 的度为5、连接到3个三角形并通过2个顶点连接到剩余网络;顶点 的度为 4、连接到2个三角形并通过2个顶点连接到剩余网络。为什么这些
embedding方法(如DeepWalk/node2vec在分类任务中大获成功,但是在结构等效structural equivalence任务中难以奏效?原因是大多数真实网络结构中,很多顶点的特征都表现出很强的同质性。如:两个具有相同政治偏好的博客更有可能被连接,而不是随机性的连接。网络中相邻的顶点更可能具有相同的特征,因此在embedding空间中趋于靠近;网络中相距较远的顶点可能具有迥异的特征,因此在embedding空间中趋于分离。这种性质和顶点的局部结构无关,因此这些
embedding方法无法捕获结构等效性。因此如果任务更依赖于结构等效性而不是同质性,则这些embedding方法容易失败。论文
《struc2vec: Learning Node Representations from Structural Identity》提出了一个学习顶点结构等效性的无监督学习框架struc2vec,它可以根据顶点的局部网络结构来识别structural identity结构角色。struc2vec的关键思想是:- 不依赖于顶点特征、边的特征、顶点的位置,仅仅依赖于顶点的局部结构来衡量顶点之间的结构相似性。我们也不需要网络是连通的,我们可以识别不同连通分量
connected componet中结构相似的顶点。 - 对结构相似性进行分层
hierarchy,随着层次的提高结构相似越严格。在层次的底部,degree相近的顶点之间是结构相似的;在层次的顶部,需要整个网络相似的顶点之间才是结构相似的。 - 采用加权随机遍历一个
multi-layer图来生成每个顶点的随机上下文。这个multi-layer是根据原始网络生成的,multi-layer图中的边是根据原始图中顶点结构相似性得到。因此有相似上下文的两个顶点很可能具有相似的结构。
DeepWalk使用随机游走从网络中生成顶点序列,并基于SkipGram学习顶点embedding。网络中接近的顶点将具有相似的上下文,因此具有相似的embedding。node2vec通过一个有偏的二阶随机游走模型来扩展了这个想法,从而在生成顶点上下文时提供了更大的灵活性。特别的,可以通过设计边的权重从而尝试捕获顶点的同质性和结构等效性。但是
DeepWalk和node2vec等方法的一个基本缺陷是:结构上相似的顶点如何其距离大于SkipGram窗口的大小,则它们永远不会共享相同的上下文。RolX是一种仅利用网络结构来明确标识顶点角色的方法。这种无监督方法基于枚举顶点的各种结构特征,然后找到联合特征空间的基向量basis vector,并为每个顶点赋予一个角色分布,这允许顶点具有多个混合的角色。在没有明确考虑顶点结构相似性的情况下,RolX可能会遗漏结构相似的顶点pair对。
考虑捕获网络中结构相似性的顶点
representation学习方法,它应该具有预期的特点:- 顶点之间结构越相似,则顶点的
embedding距离越近。因此如果两个顶点的局部网络结构相同,则它们应该具有相同的embedding。 embedding的学习不依赖于任何顶点的特征、边的特征、顶点的label、顶点的位置,仅仅依赖于顶点的局部网络结构。
考虑这两个特点,我们提出了
struc2vec框架,该框架由四个部分组成:- 结构相似性度量:确定图中每对顶点之间不同大小邻域的结构相似性。这在结构相似性度量中引入了层次
hierarchy,从而在不同层次水平上衡量结构相似性。 - 加权
multi-layer图:该图的每一层都包含原始图的所有顶点,每一层对应于hierarchy结构相似性中的某个层级。层内顶点之间边的权重与结构相似度成反比。 - 上下文生成:基于
multi-layer图上的有偏随机游走来生成顶点序列,然后为每个顶点生成上下文。这些随机游走序列更可能包含结构相似的顶点。 - 学习
embedding:采用一种技术(如SkipGram)从顶点序列中学到顶点的embedding。
struc2vec非常灵活,它不要求任何特定的结构相似性度量或者表示学习方法。- 顶点之间结构越相似,则顶点的
13.1.1 结构相似性
struc2vec需要确定两个顶点之间的结构相似性,其中不依赖于任何顶点的特征或者边的特征。另外,这种相似性应该是层次的
hierarchical:随着邻域越来越大,捕获的结构相似性越来越精确。直观地,具有相同degree的两个顶点在结构上相似。但是如果它们的邻居也具有相同的degree,则它们在结构上会更相似。随着邻居的邻居也参与其中,则相似性会得到进一步提高,即越来越精确。设
 为一个无向无权图,设 为图的直径(顶点对之间距离的最大值)。定义
为一个无向无权图,设 为图的直径(顶点对之间距离的最大值)。定义  为图中与顶点 距离为
为图中与顶点 距离为  的顶点的集合, 。根据该定义,
的顶点的集合, 。根据该定义, 表示 的直接邻居顶点的集合,
表示 的直接邻居顶点的集合, 表示和 距离为 的环。
表示和 距离为 的环。定义 为顶点集合
 的有序
的有序degree序列ordered degree sequence。通过比较顶点 和
的距离为 的环的有序degree序列,我们可以得到顶点 和 的相似性。根据不同的距离 ,我们可以得到一个
和 的相似性。根据不同的距离 ,我们可以得到一个 hierarchy层次相似性。定义 为顶点
和 的 阶结构距离,我们递归定义为:其中
 衡量了两个有序
衡量了两个有序 degree序列 的距离, 。
。其物理意义为:顶点 的
阶距离等于它们的 阶距离加上它们的第 阶环之间的距离。根据定义有:
- 是随着 递增,并且只有当 各自都存在距离为 的邻域顶点时才有定义。
- 将比较顶点 和 各自距离为
 的环的有序
的环的有序 degree序列。 - 如果 和 的 阶邻域是
isomorphic同构 的,则有 。
。
- 是随着
考虑到两个有序
degree序列 和 可能具有不同的长度,且它们的元素是位于 之间的任意整数,则如何选择合适的距离函数是一个问题。
可能具有不同的长度,且它们的元素是位于 之间的任意整数,则如何选择合适的距离函数是一个问题。论文采用
Dynamic Time Warping:DTW算法来衡量两个有序degree序列的相似性,该算法可以处理不同长度的序列。DTW算法寻找两个序列 和 之间的最佳对齐
和 之间的最佳对齐 alignment,其目标是使得对齐元素之间的距离之和最小。假设
 ,则
,则 DTW算法需要寻找一条从 出发、到达 的最短路径。假设路径长度为 ,第 个顶点为 ,则路径需要满足条件:
的最短路径。假设路径长度为 ,第 个顶点为 ,则路径需要满足条件:- 边界条件:

- 单调性:对于下一个顶点 ,它必须满足
 。即数据对齐时都是按顺序依次进行的。
。即数据对齐时都是按顺序依次进行的。 - 路径最短: ,其中
 为单次对齐的距离。
为单次对齐的距离。
如下图所示,根据边界条件,该路径需要从左下角移动到右上角;根据单调性和连续性,每一步只能选择右方、上方、右上方三个方向移动一个单位。该问题可以通过动态规划来求解。
- 边界条件:
考虑到序列
 和 中的元素为顶点的
和 中的元素为顶点的degree,我们使用以下单次对齐距离:
当 时,
 。因此如果两个
。因此如果两个degree序列相同,则每个对齐距离都是零,则序列的距离为零。如果使用传统的欧式距离,如 ,则
degree 的距离和 距离相等。
的距离和 距离相等。实际上
degree 1 vs degree 2,相比于degree 101 vs degree 102,前者的差距要大得多。而使用我们定义的dist函数有:
这正好是衡量顶点
degree差异的理想特点。
虽然论文采用
DTW来评估两个有序degree序列之间的相关性,但是struc2vec也支持使用任何距离函数。
13.1.2 加权 multi-layer 图
论文构建了一个
multi-layer加权图来编码顶点之间的结构相似性。定义 为一个multi-layer图,其中layer ()根据顶点的 阶邻域来定义。layer是一个包含顶点集合 的带权无向完全图,即包含 条边。每条边的权重由顶点之间的 阶结构相似性来决定:
的带权无向完全图,即包含 条边。每条边的权重由顶点之间的 阶结构相似性来决定:- 仅当
 有定义时,
有定义时,layer中顶点 之间的边才有定义。
之间的边才有定义。 layer中边的权重与结构距离(即 阶相似性)成反比。layer中边的权重小于等于1,当且仅当 时权重等于
时权重等于 1。- 考虑到 时随着 的增加单调增加的,因此同一对顶点 从
multi-layer图的低层到高层,边的权重是逐渐降低的。
- 仅当
对于
multi-layer图的不同层之间,我们使用有向边进行连接。每个顶点可以连接上面一层、下面一层对应的顶点。假设顶点 在 layer记作 ,则 可以通过有向边分别连接到
,则 可以通过有向边分别连接到  。
。对于跨
layer的边,我们定义其边的权重为:
为平均权重。因此
 衡量了在
衡量了在layer,顶点 和其它顶点的相似性。- 如果 在当前层拥有很多结构相似的顶点,则应该切换到更高层进行比较,从而得到更精确的相似性。
- 根据定义有
 ,因此每个每个顶点连接高层的权重不小于连接低层的权重。
,因此每个每个顶点连接高层的权重不小于连接低层的权重。 - 这里采用对数函数,因为顶点 超过层内平均权重的边的数量取值范围较大,通过对数可以压缩取值区间。
 具有 层,每一层有
具有 层,每一层有  个顶点,层内有 条边,层之间有 条边。因此
个顶点,层内有 条边,层之间有 条边。因此multi-layer图有 条边。后续会讨论如何优化从而降低生成 的计算复杂度,以及存储 的空间复杂度。
13.1.3 上下文生成
我们通过
multi-layer图 来生成每个顶点 的结构上下文。注意: 仅仅使用顶点的结构信息,而没有采用任何额外信息来计算顶点之间的结构相似性。我们也采用随机游走来生成顶点序列,这里我们考虑有偏的随机游走:根据 中边的权重来在
中随机游走。假设当前层位第 层:首先以概率
 来决定:是在当前
来决定:是在当前 layer游走还是需要切换layer游走。即以概率 来留在当前layer,以概率 来跨层。
来跨层。层间游走:如果需要切换
layer,则是移动到更上一层、还是移动到更下一层,这由层之间的有向边的权重来决定:跨层概率正比于层之间的有向边的权重。
层内游走:当随机游走保留在当前层时,随机游走从顶点
转移到顶点 的概率为:
其中分母是归一化系数。
因此随机游走更倾向于游走到与当前顶点结构更相似的顶点,避免游走到与当前顶点结构相似性很小的顶点。最终顶点的上下文中包含的更可能是和它结构相似的顶点。
对于每个顶点 ,我们从第
 层开始进行随机游走。每个顶点生成以它为起点的 条随机游走序列,每条随机游走序列的长度为
层开始进行随机游走。每个顶点生成以它为起点的 条随机游走序列,每条随机游走序列的长度为  。
。
13.1.4 学习 embedding
我们通过 来从随机游走序列中训练顶点
embedding,训练的目标是:给定序列中的顶点,最大化其上下文的概率。其中上下文由中心窗口的宽度 来给定。- 为了降低计算复杂度,我们采用
Hierarchical Softmax技巧。 - 这里也可以不适用
SkipGram,而似乎用任何其它的文本embedding技术。
- 为了降低计算复杂度,我们采用
13.1.5 优化
为了构建
我们需要计算每一层每对顶点之间的距离 ,而 需要基于 DTW算法在两个有序degree序列上计算。经典的DTW算法的计算复杂度为 ,其快速实现的计算复杂度为 ,其中 为最长序列的长度。
,其中 为最长序列的长度。令
 为网络中的最大
为网络中的最大 degree,则对于任意顶点 和邻域大小 , degree序列的长度满足 。由于每一层有
 对顶点,因此计算第 层所有距离的计算复杂度为
对顶点,因此计算第 层所有距离的计算复杂度为  。
。最终构建 的计算复杂度为
 。
。这里我们介绍一系列优化来显著减少计算复杂度和空间复杂度。
优化一:降低有序
degree序列的长度。为了降低比较长序列距离的代价,我们对有序
degree序列进行压缩:对序列中出现的每个degree,我们保存它出现的次数。压缩后的有序degree序列由该degree,以及它出现的次数构成的元组来组成。注意:压缩后的有序degree序列也是根据degree进行排序。由于网络中很多顶点往往具有相同的
degree,因此压缩后的有序degree序列要比原始序列小一个量级。令 为压缩后的有序
degree序列,它们的元素都是元组的形式。则我们在DTW中的dist函数修改为:
其中 ,
 都是
都是 degree, 都是degree对应出现的次数。注意:使用压缩的
degree序列会使得具有相同degree的原始序列片段之间的比较。原始的DTW算法是比较每个degree,而不是比较每个degree片段,因此上式是原始DTW的近似。由于
DTW现在在 上计算,而它们要比 短得多,因此可以显著加速
上计算,而它们要比 短得多,因此可以显著加速 DTW的计算速度。优化二:降低成对顶点相似度计算的数量。
在第
层,显然没有必要计算每对顶点的相似度。考虑degree相差很大的一对顶点(如degree=2和degree=20),即使在 层它们的结构距离也很大。由于顶点之间的结构距离随着 的增大而增大,因此当 时它们的结构距离更大。因此这样的一对顶点在  中的边的权重很小,则随机游走序列不太可能经过这种权重的边,因此在 中移除这类边不会显著改变模型。
中的边的权重很小,则随机游走序列不太可能经过这种权重的边,因此在 中移除这类边不会显著改变模型。我们将每一层需要计算相似度的数量限制为:每个顶点最多与
 个顶点计算相似度。令顶点 需要计算相似度的邻居顶点集合为
个顶点计算相似度。令顶点 需要计算相似度的邻居顶点集合为  ,则 需要包含哪些几乎和 结构相似的顶点,并且应用到所有
,则 需要包含哪些几乎和 结构相似的顶点,并且应用到所有 layer。我们取和 的
degree最相似的顶点作为 。- 首先对全网所有顶点的有序
degree序列进行二分查找,查找当前顶点 的degree - 然后沿着每个搜索方向(左侧、右侧)获取连续的
 个顶点。
个顶点。
计算 的计算复杂度为
 ,因为我们需要对全网顶点根据
,因为我们需要对全网顶点根据 degree进行排序。现在 每一层包含
 条边 ,而不是 条边。
条边 ,而不是 条边。- 首先对全网所有顶点的有序
优化三:降低层的数量。
中的层的数量由网络直径 来决定。但是实际上当 的值足够大时,评估两个顶点之间的结构相似性就没有任何意义。因为当 接近  时, 和 这两个序列都非常短,这使得 和
时, 和 这两个序列都非常短,这使得 和  几乎相等。
几乎相等。因此我们可以将 的层的数量限制为一个固定的常数
 ,从而仅仅采用最重要的一些层来评估结构相似性。这显著减少了构建 的计算需求和内存需求。
,从而仅仅采用最重要的一些层来评估结构相似性。这显著减少了构建 的计算需求和内存需求。尽管上述优化的组合会影响顶点的结构
embedding,但是我们实验证明:这些优化的影响非常小,甚至是有益的。因此降低模型计算量和内存需求的好处远远超出了它们的不足。
13.2 实验
13.2.1 杠铃图
我们定义
 为
为 (h,k)-barbell图:- 杠铃图包含两个完全图 和
 ,每个完全图包含 个顶点
,每个完全图包含 个顶点 - 两个顶点
 和 作为
和 作为 bridge,我们连接 到 、
到 、 到
到
杠铃图中包含大量结构身份
structural identity相同的顶点。- 定义
 ,则所有的顶点 为结构身份相同的。
,则所有的顶点 为结构身份相同的。  顶点对之间也是结构身份相同的。
顶点对之间也是结构身份相同的。- 这对
bridge也是结构身份相同的。
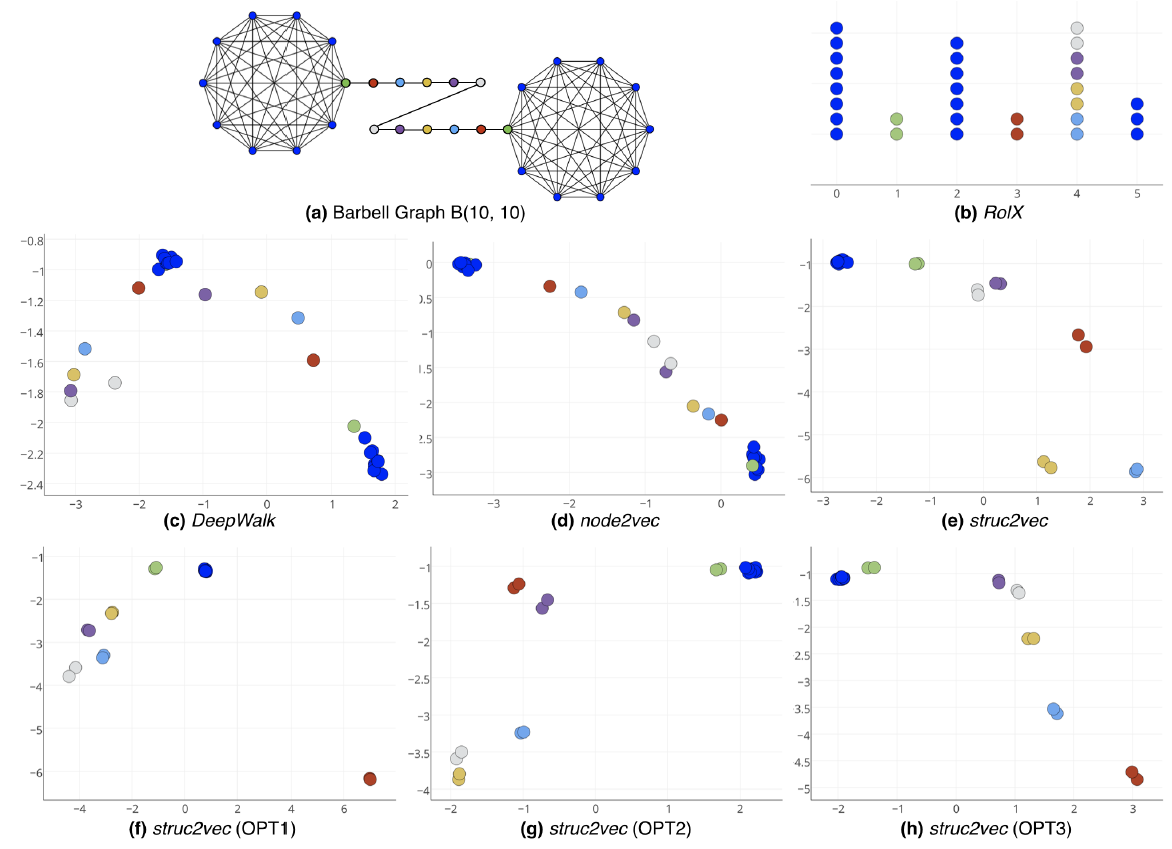
下图给出了
 杠铃图,其中结构等价的顶点以相同的颜色表示。
杠铃图,其中结构等价的顶点以相同的颜色表示。- 杠铃图包含两个完全图 和
我们使用
DeepWalk,node2vec,struc2vec等模型学习杠铃图中顶点的embedding。这些模型都采用相同的参数:每个顶点开始的随机游走序列数量20、每条游走序列长度80、SkipGram窗口大小为5。对于node2vec有 。
。我们预期
struc2vec下图给出了各模型针对 杠铃图学到的
embedding。DeepWalk无法捕获结构等效性。这是符合预期的,因为DeepWalk并不是为结构等效性而设计的。struc2vec能够学到间隔良好的等效类别embedding,从而将结构等效的顶点放在embedding空间中相近的位置。struc2vec还能够捕获结构层次structural hierarchy:虽然顶点 和 都不等价,但是在从结构上看 和 比 和 更相似。表现在 embedding空间上, 和 的距离更近。- 我们提出的三个优化并为对
embedding的质量产生任何重大影响。实际上优化一的embedding中,结构等效的顶点甚至更加靠近。
- 图
b给出了RolX的结果。模型一共确定了六个角色,其中角色2和角色4捕获了正确的结构类别,蓝色类别被分配到三个类别(角色1、3、6) ,角色5包含了剩余的类别。
13.2.2 Karate 网络
Zachary's Karate Club是一个由34个顶点、78条边组成的网络,其中每个顶点代表俱乐部成员、边表示两个成员是否在俱乐部以外产生互动,因此边通常被解释为成员之间的好友关系。我们的网络由该网络的两个拷贝 组成,其中
 都有一个镜像顶点 。我们还通过在镜像顶点对
都有一个镜像顶点 。我们还通过在镜像顶点对 (1,37)之间添加一条边来连通 。尽管
。尽管 struc2vec可以建模分离的连通分量,但是DeepWalk和node2vec无法训练。为了与DeepWalk/node2vec基准方法进行公平的比较,我们添加了这条边。下面给出了镜像网络,其中结构相等的顶点采用相同的颜色表示。
我们使用
DeepWalk,node2vec,struc2vec等模型学习镜像图中顶点的embedding。这些模型都采用相同的参数:每个顶点开始的随机游走序列数量5、每条游走序列长度15、SkipGram窗口大小为3。对于node2vec有 。DeepWalk和node2vec学习的embedding可视化结果如下图所示。可以看到,它们都无法识别结构等效的顶点。struc2vec成功的学到顶点的结构特征,并正确捕获到结构等效性。镜像顶点pair对在embedding空间中距离很近,并且顶点以一个复杂的结构层次聚合在一起。另外,顶点
1和34在网络中具有类似领导者的角色,struc2vec成功捕获了它们的结构相似性,即使它们之间不存在边。RolX一共识别出28个角色。注意:顶点1/34被分配到不同角色中,顶点1/37也被分配到不同角色中。一共34对镜像顶点pair对中仅有7对被正确分配。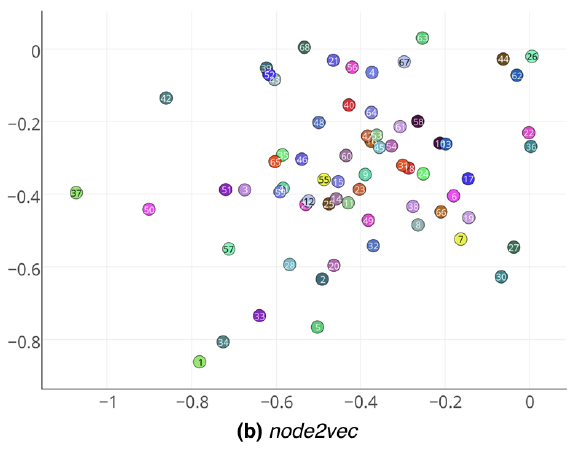

我们测量了每个顶点和它的镜像顶点之间的距离、每个顶点和子图内其它顶点的距离,下图给出
node2vec和struc2vec学到的 的这两种距离分布。横轴为距离,纵轴为超过该距离的顶点对的占比。对于
node2vec,这两个分布几乎相同。这表明node2vec并未明显的区分镜像顶点pair对和非镜像顶点pair对,因此node2vec无法很好识别结构等效性。对于
struc2vec,这两个分布表现出明显的差异。94%的镜像pair对之间的距离小于0.25,而68%的非镜像pair对之间的距离大于0.25。非镜像
pair对的平均距离是镜像pair对平均距离的5.6倍,而node2vec这一比例几乎为1。
接下来我们评估所有顶点对之间的距离(通过
来衡量),以及它们在 embedding空间中的距离(通过欧式距离来衡量)的相关性。我们分别计算Spearman相关系数和Pearson相关系数,结果如下图所示。这两个系数表明:对于每一层这两个距离都存在很强的相关性。这表明
embedding确实刻画了顶点之间的结构相似性。
13.2.3 分类任务
我们考虑一个空中交通网络,它是一个无权无向图,每个顶点表示机场,每条边表示机场时间是否存在商业航班。我们根据机场的活跃水平来分配
label,其中活跃水平根据航班流量或者人流量为衡量。数据集:
- 巴西空中交通网络:包含
2016年1月到2016年12月从国家民航局ANAC收集的数据。该网络有131个顶点、1038条边,网络直径为5。机场活跃度是通过对应年份的着陆总数与起飞总数来衡量的。 - 美国空中交通网络:包含
2016年1月到2016年10月从美国运输统计局收集的数据。该网络有1190个顶点、13599条边,网络直径为8。机场活跃度是通过对应年份的人流量来衡量的。 - 欧洲空中交通网络:包含
2016年1月到2016年11月从欧盟统计局收集的数据。该网络包含399个顶点、5995条边,网络直径为5。机场活跃度是通过对应年份的着陆总数与起飞总数来衡量的。
对于每个机场,我们将其活跃度的标签分为四类:对每个数据集我们对活跃度的分布进行取四分位数从而分成四组,然后每一组分配一个类别标签。因此每个类别的样本数量(机场数量)都相同。
另外机场类别更多的与机场角色密切相关。
- 巴西空中交通网络:包含
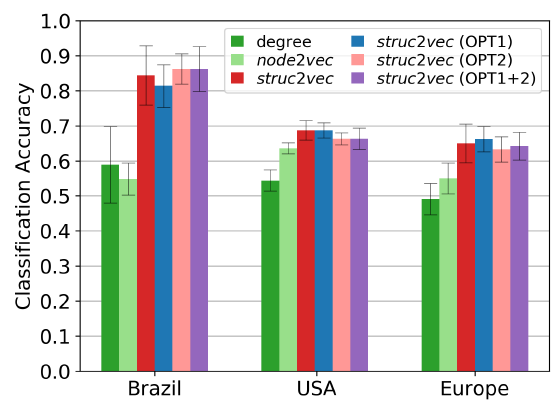
我们使用
struc2vec和node2vec来学习每个网络的顶点embedding,其中我们通过grid search来为每个模型选择最佳的超参数。然后我们将学到的
embedding视为特征来训练一个带L2正则化的one-vs-rest逻辑回归分类器。我们还考虑直接将顶点的degree作为特征来训练一个逻辑回归分类器,从而比较使用原生特征和embedding特征的区别。由于每个类别的规模相同,因此我们这里使用测试准确率来评估模型性能。我们将分类模型的数据随机拆分为
80%的训练集和20%的测试集,然后重复实验10次并报告平均准确率。结论:
struc2vec模型学到的embedding明显优于其它方法,并且其优化几乎没有产生影响。node2vec模型学到的embedding的平均性能甚至略低于直接使用顶点degree,这表明在这个分类任务中,顶点的结构相似性起到了重要作用。
13.2.4 健壮性和可扩展性
为了说明
struc2vec对噪音的健壮性,我们从网络中随机删除边从而直接修改其网络结构。给定图 ,我们以概率
 随机采样 图中的边从而生成新的图
随机采样 图中的边从而生成新的图  ,这相当于图 的边以概率
,这相当于图 的边以概率  被删除。
被删除。我们从
Facebook网络中随机采样,该网络包含224个顶点、3192条边,顶点degree最大为99最小为1。我们采用不同的 来生成两个新的图 和 ,我们重新标记  中的顶点从而避免两个顶点编号相同。因此这里也存在一种“镜像”关系:原始
中的顶点从而避免两个顶点编号相同。因此这里也存在一种“镜像”关系:原始Facebook网络中的顶点会同时出现在 和 中。我们将这两个子图的并集来作为
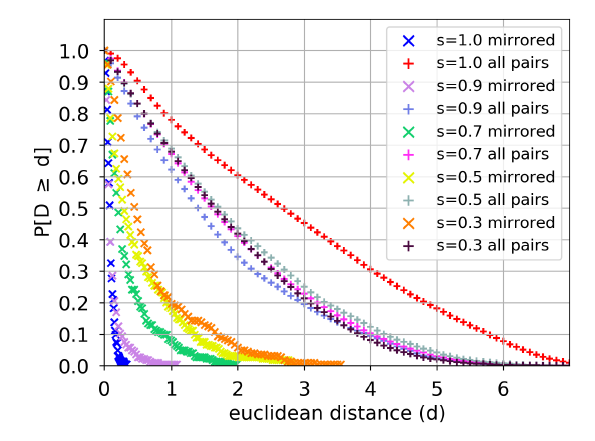
struc2vec的输入。下图给出了不同的 值,struc2vec学到的所有顶点pair对之间的距离分布。其中x标记的是镜像顶点pair对之间的距离,+标记的是所有顶点pair对之间的距离。当
 时,两个距离分布明显不同。所有顶点
时,两个距离分布明显不同。所有顶点pair对之间的平均距离要比镜像顶点pair对之间的平均距离大21倍。当 时,两个距离分布仍然非常不同。进一步减小
不会显著影响所有顶点 pair对的距离分布,但是会缓缓改变镜像顶点pair对的距离分布。即使在 时,这意味着原始边同时出现在
和 中的概率为 0.09,struc2vec仍然会将镜像顶点pair对进行很好的区分。这表明即使在存在结构噪音的情况下,
struc2vec在识别结构等效性方面仍然具有很好的鲁棒性。
我们将采用优化一、优化二的
struc2vec应用于Erd¨os-R´enyi图,我们对每个顶点采样10个随机游走序列,每个序列长度为80,SkipGram窗口为10,embedding维度为128。为加快训练速度,我们使用带负采样的SkipGram.为评估运行时间,我们在顶点数量从
100到100万、平均degree为10的图上训练struc2vec。每个实验我们独立训练10次并报告平均执行时间。其中training time表示训练SkipGram需要的额外时间。下图给出了
log-log尺度的训练时间,这表明struc2vec是超线性的,但是接近 (虚线)。因此尽管 在最坏情况下在时间和空间上都是不利的,但是实际上它仍然可以扩展到非常大的网络。
(虚线)。因此尽管 在最坏情况下在时间和空间上都是不利的,但是实际上它仍然可以扩展到非常大的网络。

