
-
论文
《Attentional Factorization Machines: Learning the Weight of Feature Interactions via Attention Networks》提出了Attentional Factorization Machine:AFM模型,该模型通过attention机制来自动学习每个二阶交叉特征的重要性。与
Wide&Deep以及DeepCross等模型相比,AFM结构简单、参数更少、效果更好。同时AFM具有很好的可解释性:通过注意力权重可以知道哪些交叉特征对于预测贡献较大。
AFM模型和NFM模型一脉相承,其底层架构基本一致。给定经过
one-hot编码之后的输入向量 ,其中特征 表示第 个特征不存在。则
表示第 个特征不存在。则 AFM的预测结果为:
- 类似
FM,AFM的第一项为全局偏置,第二项为一阶特征。 - 与
FM不同,AFM的第三项 对交叉特征进行建模,它是一个多层前馈神经网络,包含embedding层、Pair-wise Interaction成对交叉层、Attention-based Pooling层、输出层。如下图所示(仅仅包含 )。
)。
- 类似
embedding层将每个feature映射到一个dense vector representation,即特征 映射到向量 。
映射到向量 。一旦得到
embedding向量,则输入 就可以表示为:
就可以表示为:由于输入
 的稀疏性, 只需要保存非零的特征。
的稀疏性, 只需要保存非零的特征。注意:这里使用输入特征
 来调整
来调整 embedding向量,而不是简单的从embedding table中查找。这样做的好处是可以统一处理实值特征real valued feature。和
NFM的Bi-Interaction层不同,AFM的Pair-wise Interaction层将 个向量扩充为 个交叉向量,每个交叉向量是两个
个交叉向量,每个交叉向量是两个 embedding向量的逐元素积。 为 中非零元素数量。假设输入 的非零元素下标为
 ,对应的
,对应的 embedding为 ,则Pair-wise Interaction层的输出为:
其中 表示逐元素乘积,
 表示成对下标集合。
表示成对下标集合。与之相比,
NFM的Bi-Interaction层输出为:一旦得到
Pair-wise Interaction层的 个交叉向量,则可以通过一个 sum pooling层来得到一个池化向量:它刚好就是
Bi Interaction层的输出 。因此Pair-wise Interaction层+sum pooling 层=Bi Interaction 层。Attention-based Pooling层:与Bi Interaction pooling操作不同,Attention-based Pooling操作采用了attention机制:
其中 是交叉特征
 的
的attention score,可以理解为交叉特征 的权重。学习
 的一个方法是直接作为模型参数来学习,但这种方法有个严重的缺点:对于从未在训练集中出现过的交叉特征,其
的一个方法是直接作为模型参数来学习,但这种方法有个严重的缺点:对于从未在训练集中出现过的交叉特征,其 attentioin score无法训练。为解决该问题,论文使用一个
attention network来训练 。attention network的输入为 个交叉特征向量,输出为 。
个交叉特征向量,输出为 。
其中 都是模型参数,
 为
为 attention network的隐向量维度,称作attention factor。输出层用于输出预测得分:
最终模型为:

模型的参数为: 。
- 当移除
attention network时,AFM模型退化为NFM-0模型,即标准的FM模型。 - 和
NFM相比,AFM模型缺少隐层来提取高阶特征交互。
- 当移除
-
对于回归任务,损失函数为平方误差:

对于分类任务,损失函数为
hinge loss或者logloss。对于排序任务,损失函数为
pairwise personalized ranking loss或者contrastive max-margin loss。
9.2 实验
数据集:
Frappe数据集:给出了不同上下文时用户的app使用日志记录,一共包含96203个app。除了
userID, appID之外,每条日志还包含8个上下文特征:天气、城市、daytime(如:早晨、上午、下午) 等。采用
one-hot编码之后,特征有 5382 维;label = 1表示用户使用了app。数据集:
GroupLens发布的最新MovieLens数据集的完整版,包含17045个用户在23743个item上的49657类标签。将
userID,movieID,tag进行one-hot编码之后,特征有90445维;label = 1表示用户给movie贴了tag。
由于这两个数据集只包含正类(即:
label = 1),因此需要通过采样来生成负类,负类数量和正类数量的比例为2:1。- 对于
Frappe数据集,对每条记录,随机采样每个用户在上下文中未使用的其它两个app。 - 对于
MovieLens数据集,对每个用户每个电影的每个tag,随机分配给该电影其它两个该用户尚未分配的tag。
对于每个数据集拆分为训练集(70%)、验证集(20%)、测试集(10%)。
评估标准:验证集或者测试集的均方根误差
RMSE。注意:由于论文采用回归模型来预测,因此预测结果可能大于
+1(正类的label)护着小于-1(负类的label)。因此如果预测结果超过+1则截断为+1、低于-1则截断为-1。模型比较
baseline:LibFM:FM的官方实现(基于 C++),采用SGD学习器。HOFM:基于tensorflow实现的高阶FM,这里设置为3阶。因为MovieLens数据集只有三个特征:User,Item,Tag。Wide&Deep:Wide&Deep模型,其中deep part包含三层隐层,每层维度分别为1024,512,256;wide部分和FM的线性部分相同。DeepCross:DeepCross模型,其中包含 5层残差网络,每层维度为512,512,256,128,64。
超参数配置:
优化目标:平方误差。
//学习率:所有模型的学习率通过超参数搜索得到,搜索范围
[0.005,0.01,0.02,0.05]正则化:
线性模型
LibFM,HOFM使用 正则化,正则化系数搜索范围
正则化,正则化系数搜索范围 [1e-6,5e-6,1e-5,...,1e-1]。神经网络模型
Wide&Deep,DeepCross,NFM执行dropout,遗忘比例搜索范围[0,0.1,0.2,...,0.9]。实验发现
dropout在Wide&Deep,NFM中工作良好,但是在DeepCross工作较差。所有模型都采用早停策略
early stopping。
优化策略:
libFM使用常规SGD优化,其它模型使用mini-batch Adagrad优化。其中
Frappe数据集的Batch Size = 128,MovieLens数据集的Batch Size = 4096。Batch Size的选择要综合考虑训练时间和收敛速度。更大的Batch Size使得每个epoch的训练时间更短,但是需要更多的epoch才能收敛。attention factor默认为 256。
9.2.1 超参数探索
首先考察
dropout超参数。设置 从而使得attention network没有正则化。另外移除
attention network使得网络退化为FM模型来做比较。libFM作为baseline。结论:
选择合适的
dropout值,AFM和FM都能够得到显著的提升。这证明了在Pair-wise Interaction层执行dropout的有效性。我们的
FM模型比 效果更好,有两个原因:libFM采用SGD来优化,学习率是固定的。我们的FM是通过Adagrade来优化,采用自适应学习率因此优化效果更好。LibFM采用 正则化来缓解过拟合,而我们的 FM采用dropout。后者缓解过拟合的效果更好。
AFM的效果比FM和libFM好得多,即使是当dropout = 0时(即:未采取任何正则化)AFM的效果仍然很好。这充分证明了attention network的效果。
然后考察
正则化系数。当选择合适的 dropout参数之后,我们考察对attention network执行 正则化的效果。结论:当
 时,模型效果得到改善。这证明了
时,模型效果得到改善。这证明了 attention network正则化的效果,能进一步改善模型的泛化能力。同时说明了:仅仅Pair-wise Interaction层执行dropout对于缓解过拟合是不够的。注意:
FM和LibFM均没有attention network,因此它们在图上都是直线。
9.2.2 attention network
首先考察
attention factor的影响。下图给出
attention network不同的隐向量维度(attention factor)下,模型的性能。其中每种隐向量维度都各自独立的选择了最合适的 。
。结论:
AFM对于attention factor的变化比较稳定。极端情况下,即使attention factor =1,此时 退化为一个向量、attention network退化为一个广义线性模型,AFM的效果仍然很好。这证明了
AFM设计的合理性:通过attention network来评估特征的representation vector之间交互的重要性。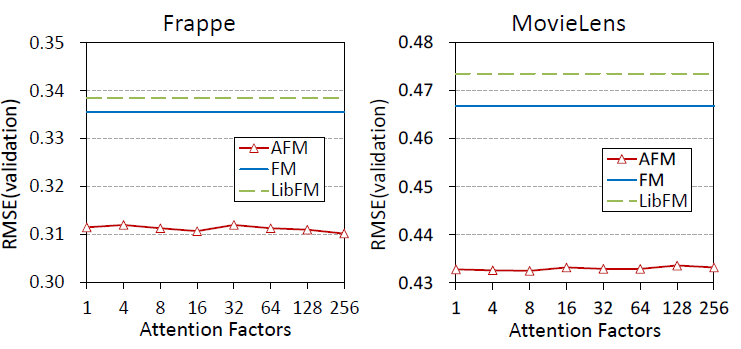
然后评估
AFM和FM在每个epoch的训练误差和测试误差。 可以看到:AFM收敛速度比FM收敛速度更快。- 对于
Frappe,AFM训练误差、测试误差都比FM下降很多,说明AFM对于已知数据、未知数据都拟合较好。 - 对于
MovieLens,尽管AFM训练误差更大,但是它的测试误差更小,说明了AFM泛化能力更强。
- 对于
最后可以通过
attention score来解释每个交叉特征的重要性。首先固定所有的
 (即:每个交叉特征都是同等重要的),训练模型
(即:每个交叉特征都是同等重要的),训练模型 A。该模型等价于FM模型,在下表中记作FM。然后在模型
A的基础上,固定所有的embedding向量,仅训练attention network,得到模型B。该模型在下表中记作FM + A(A指的是Attention) 。在这一步发现模型
B比模型A提升了大约 3%,这也证明了attention network的有效性。最后用模型
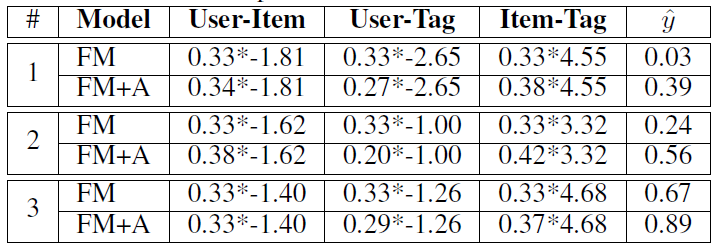
B预测从测试集中随机挑选的 3 个正样本,观察attention score。
下表中,表格中每一项表示的是
attention sore x interaction score。其中attention score总和为1,interaction score由 来决定。从表中可知:
FM模型中,不同交叉特征的重要性都是相同的。AFM模型中,Iter-Tag交叉特征更为重要。
9.2.3 模型比较
下表给出了所有模型在两个数据集上的效果(测试误差)以及模型大小。其中
embedding = 256,M表示百万。结论:
AFM参数最少,同时效果最好。这证明了AFM模型的有效性,尽管它是一个浅层模型,但是其性能优于深层模型。HOFM相对于FM略有改善,这说明FM仅建模二阶特征交互的局限性,以及建模高阶特征交互的有效性。DeepCross模型效果最差。论文发现dropout在DeepCross上效果很差,原因可能是 的影响。

