
-
所谓的删除,即指定该该隐单元的输出都为 0。
一旦隐单元的权重为0,则该隐单元对后续神经元的影响均为 0 。
输入层和输出层的神经元不会被删除,因为这两个层的神经元的数量是固定的。
理论上可以对输入层应用
dropout,使得可以有机会删除一个或者多个输入特征。但实际工程中,通常不会这么做。隐单元删除发生在一个训练样本的训练期间。
- 不同的训练样本,其删除的隐单元的集合是不同的,因此裁剪得到的小网络是不同的。
- 不同的训练样本,隐单元被删除的概率 都是相同的。
- 在不同
batch之间的同一个训练样本,其删除的隐单元的集合也是不同的。
在不同的梯度更新周期,会从完整的网络中随机删除不同的神经元,因此裁剪得到的小网络是不同的。
但是在这个过程中,隐单元被删除的概率是相同的。
可以指定某一个隐层或者某几个隐层执行
dropout,而没有必要针对所有的隐层执行dropout。可以对网络的每个隐单元指定不同的删除概率,但实际工程中,通常不会这么做。
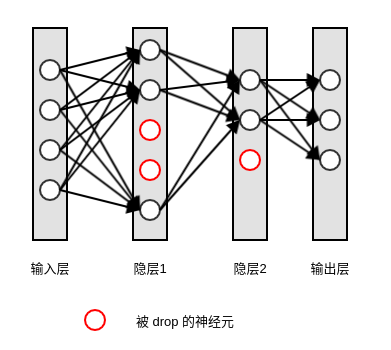
定义一个掩码向量 ,它给出了哪些隐单元被保留哪些隐单元被删除:掩码为
0的位置对应的隐单元被删除,掩码为1的位置对应的隐单元被保留。定义
 为参数 和掩码
为参数 和掩码  共同定义的模型代价,
共同定义的模型代价,dropout的目标是最小化 。- 这里采用期望,因为掩码向量
 是一个随机向量,对于每个训练样本 都可能不同。
是一个随机向量,对于每个训练样本 都可能不同。 - 因为掩码向量具有指数多个,因此期望包含了指数多项。实际应用中,可以通过抽样 来获得期望的无偏估计。
- 这里采用期望,因为掩码向量
dropout训练与bagging训练不同:bagging中,假设所有的子模型都是独立的。dropout中,所有的子模型是共享参数的,每个子模型继承了基础神经网络的不同子集。参数共享使得在有限的内存下训练指数数量的子模型变得可能。
bagging中,每个子模型在其相应的训练集上训练到收敛。dropout中,大部分子模型都没有显式的被训练(因为指数量级的神经网络不可能被训练完成)。我们只是对子模型的某些部分训练单个
step,同时参数共享使得子模型的剩余部分能够有较好的参数值。
dropout仅仅用于神经网络的训练阶段,在网络的测试阶段并不会删除神经元,而是使用所有的神经元。因为在测试期间,不希望输出是随机的。如果在测试阶段使用
dropout,则理论上需要运行多次dropout测试过程,然后对输出结果取加权平均(或者几何平均)。这种做法的结果与不采用 的测试结果相同,反而计算效率更低。在
dropout情况下,每个子模型的输出为概率分布 ,不同的掩码 就定义了不同的子模型。
就定义了不同的子模型。其中
 是训练时 的概率分布。之所以不采用
是训练时 的概率分布。之所以不采用  这种代数平均(
这种代数平均(k为子模型数量),是因为 掩码生成的概率不一定是均匀的。上式包含了指数量级的项,不可能计算出来。但是可以通过采样来近似推断,即对多个掩码对应的输出进行平均。通常 10-20 个掩码就足以获取不错的表现。
除了子模型输出的加权平均之外,还可以采用几何平均:

其中 为所有的可以被丢弃的单元的数量,其丢弃/保留组合有
 种。
种。这里采用的是均匀分布的 (也可以采用非均匀分布),设丢弃和保留的概率都是
 。
。多个概率分布的几何平均不一定是个概率分布,因此为了保证结果是一个概率分布,概率归一化为:
其中要求:没有任何一个子模型给出所有事件的概率为都为 0 (否则会导致
 都为 0 )。
都为 0 )。
实际应用中,并不需要直接求解 。通常通过评估某个模型的
 来近似 。该模型这样产生:该模型与
来近似 。该模型这样产生:该模型与dropout的基础模型具有相同的单元;该模型单元 输出的权重需要乘以保留该单元 的概率。
输出的权重需要乘以保留该单元 的概率。这种策略叫做权重比例推断法则。目前这种做法在深度非线性网络上工作良好,但是没有任何理论上的证明。
考虑
softmax单元。假设 表示 个输入变量,则有:
表示 个输入变量,则有: 。其中 表示分类的类别,
。其中 表示分类的类别,  表示输出的第 个分量。
表示输出的第 个分量。假设给定掩码
 。其中 ,为二值随机变量:若它取值为
。其中 ,为二值随机变量:若它取值为 0则表示输入 被遗忘;若它取值为
被遗忘;若它取值为 1则表示输入 被保留。且假设 。
。则: 。其中
 表示逐元素的相乘。
表示逐元素的相乘。softmax单元的输出为: 。其中 :
化简上式:
其中
 表示矩阵 的第
表示矩阵 的第  列; 表示向量点乘。
列; 表示向量点乘。忽略对
不变的项,有:考虑
 ,它就是 。则有:
,它就是 。则有:
因此,
softmax单元采用dropout的结果就是权重为 的softmax单元。权重比例推断法在
softmax以外的情况也是精确的,但是它对于非线性的深度模型仅仅是一个近似。
dropout不限制使用的模型或者训练过程,另外其计算非常方便。训练过程中使用
dropout时,产生 个随机二进制数与每个权重相乘。
个随机二进制数与每个权重相乘。dropout对于每个样本每次更新只需要 的计算复杂度。根据需要也可能需要 的存储空间来保存这些二进制数(直到反向传播阶段)。
的存储空间来保存这些二进制数(直到反向传播阶段)。在预测过程中,计算代价与不使用
dropout是一样的。
dropout的缺点是:代价函数 不再被明确定义,因为每次迭代时都会随机移除一部分隐单元。虽然
dropout在模型训练的每一步上所做的工作是微不足道的(仅仅是随机地保留某些单元),但是在完整的训练结果上,该策略的效果非常显著。网络中的不同隐层的删除概率可以是变化的:
- 对于某些层,如果隐单元数量较少,过拟合的程度没有那么严重,则该层的
 值可以小一些。
值可以小一些。 - 对于一些层,如果隐单元数量较多,过拟合较严重,则该层 的值可以较大。
- 对于一些层,如果不关心其过拟合问题,则该层的 可以为
0。
- 对于某些层,如果隐单元数量较少,过拟合的程度没有那么严重,则该层的
使用
dropout有两点注意:在训练期间如果对某个单元的输入神经元执行了
dropout,则推断期间该单元的输出要进行调整。假设该单元的输出为 ,则需要调整为
 ,从而保证不影响该单元的输出值。
,从而保证不影响该单元的输出值。在测试期间,不必使用
dropout。
由于针对每个训练样本,训练的都是一个规模极小的网络,因此
dropout也是一种正则化策略,它减少了模型的有效容量effective capacity。为了抵抗模型有效容量的降低,必须增大模型的规模,此时需要更多的训练迭代次数。
- 对于非常大的数据集,
dropout正则化带来的泛化误差减少得很小。此时使用dropout带来的更大模型的计算代价可能超过了正则化带来的好处。 - 对于极小的数据集,
dropout不会很有效。
- 对于非常大的数据集,
除非模型发生过拟合,否则不要轻易使用
dropout。因为计算机视觉领域通常缺少足够的数据,所以非常容易发生过拟合。因此
dropout在计算机视觉领域大量应用。Srivastava et al.(2014)显示:dropout比其他标准的、计算开销较小的正则化项(如 正则化)更加有效。dropout也可以与其他形式的正则化合并,进一步提升模型的泛化能力。dropout训练时随机丢弃隐单元:这种随机性并不是产生正则化效果的必要条件,它仅是近似所有可能的子模型总和的一种方法。
这种随机性也不是产生正则化效果的充分条件。
dropout正则化效果主要来源于施加到隐单元的掩码噪声。这可以看作是对输入信息自适应破坏的一种形式。- 的噪声是乘性的,而传统的噪声注入是加性的。

