
-
 表示用户 对物品
表示用户 对物品  的评分。
的评分。其中已知部分用户在部分物品上的评分: 。目标是求解剩余用户在剩余物品上的评分:

其中 为
 的补集。
的补集。通常评分问题是一个回归问题,模型预测结果是评分的大小。此时损失函数采用 等等。
也可以将其作为一个分类问题,模型预测结果是各评级的概率。此时损失函数是交叉熵。
当评分只有
0和1时,这表示用户对商品 “喜欢/不喜欢”,或者 “点击/不点击”。这就是典型的点击率预估问题。
事实上除了已知部分用户在部分物品上的评分之外,通常还能够知道一些有助于影响评分的额外信息。如:用户画像、用户行为序列等等。这些信息称作上下文
context。对每一种上下文,我们用变量 来表示,
 为该上下文的取值集合。假设所有的上下文为 ,则模型为:
为该上下文的取值集合。假设所有的上下文为 ,则模型为:
上下文的下标从
3开始,因为可以任务用户 和商品 也是上下文的一种。如下图所示为评分矩阵,其中:
所有离散特征都经过特征转换。
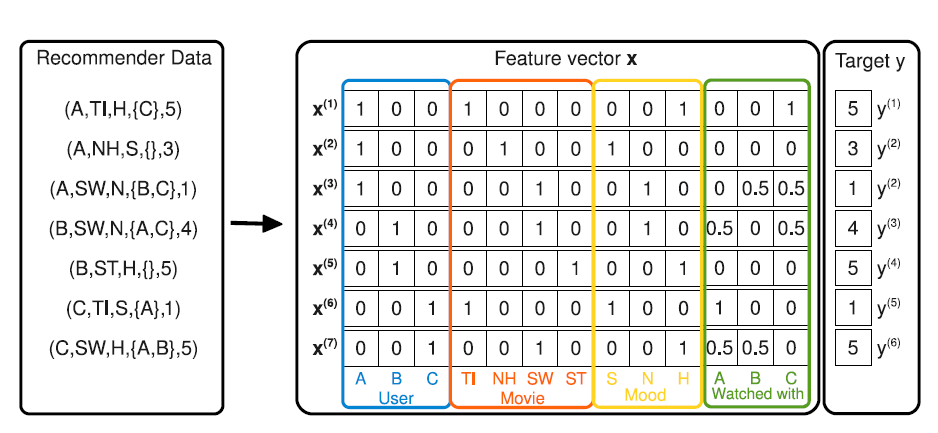
上下文特征
context类似属性property特征,它和属性特征的区别在于:属性特征是作用到整个用户(用户属性)或者整个物品(物品属性),其粒度是用户级别或者物品级别。
如:无论用户 “张三” 在在评分矩阵中出现多少次,其性别属性不会发生改变。
上下文特征是作用到用户的单个评分事件上,粒度是事件级别,包含的评分信息更充足。
如:用户 ”张三“ 在评价某个电影之前已经看过的电影,该属性会动态改变。
事实上属性特征也称作静态画像,上下文特征也称作动态画像。业界主流的做法是:融合静态画像和动态画像。
另外,业界的经验表明:动态画像对于效果的提升远远超出静态画像。
Multiverse Recommendation基于矩阵分解技术求解该问题,它将原始的评分矩阵分解为一个小的矩阵 和 个因子矩阵 :
个因子矩阵 :
其中:
这种方式存在三个问题:
- 计算复杂度太高:假设每个特征的维度都是
 ,则计算复杂度为 。一旦上下文特征数量 增加,则计算复杂度指数型增长。
,则计算复杂度为 。一旦上下文特征数量 增加,则计算复杂度指数型增长。 - 仅能对离散型
categorical上下文特征建模:无法处理数值型特征、离散集合型categorical set特征。 - 交叉特征高度稀疏:这里执行的是
K路特征交叉(前面的POLY2模型是两路特征交叉),由于真实应用场景中单个特征本身就已经很稀疏,K路特征交叉使得数据更加稀疏,难以准确的预估模型参数。
- 计算复杂度太高:假设每个特征的维度都是
Fast Context-aware Recommendations with Factorization Machines论文提出了FM算法来解决该问题。和
POLY2相同FM也是对二路特征交叉进行建模,但是FM的参数要比POLY2少得多。将样本重写为:
则
FM模型为:
其中 是交叉特征的参数,它由一组参数定义:

即:
模型待求解的参数为:

其中:
- 表示全局偏差
 用于捕捉第 个特征和目标之间的关系
用于捕捉第 个特征和目标之间的关系 用于捕捉 二路交叉特征和目标之间的关系。
用于捕捉 二路交叉特征和目标之间的关系。 代表特征 的
代表特征 的representation vector,它是 的第 列。
的第 列。
FM模型的计算复杂度为 ,但是经过数学转换之后其计算复杂度可以降低到 :
,但是经过数学转换之后其计算复杂度可以降低到 :
因此有:
其计算复杂度为
 。
。模型可以用于求解分类问题(预测各评级的概率),也可以用于求解回归问题(预测各评分大小)。
对于回归问题,其损失函数为
MSE均方误差:对于二分类问题,其损失函数为交叉熵:

其中:
- 评级集合为 一共两个等级
 为样本 预测为评级
为样本 预测为评级  的概率,满足:
的概率,满足:
损失函数最后一项是正则化项,为了防止过拟合, 。其中
 为参数 的正则化系数,它是模型的超参数。
为参数 的正则化系数,它是模型的超参数。可以针对每个参数配置一个正则化系数,但是选择合适的值需要进行大量的超参数选择。论文推荐进行统一配置:
- 对于 ,统一配置正则化系数为
- 对于
 ,统一配置正则化系数为
,统一配置正则化系数为
FM模型可以处理不同类型的特征:离散型特征
categorical:FM对离散型特征执行one-hot编码。如,性别特征:“男” 编码为
(0,1),“女” 编码为(1,0)。离散集合特征
categorical set:FM对离散集合特征执行类似one-hot的形式,但是执行样本级别的归一化。如,看过的历史电影。假设电影集合为:“速度激情9,战狼,泰囧,流浪地球”。如果一个人看过 “战狼,泰囧,流浪地球”, 则编码为
(0,0.33333,0.33333,0.33333)。数值型特征
real valued:FM直接使用数值型特征,不做任何编码转换。
FM的优势:给定特征
representation向量的维度时,预测期间计算复杂度是线性的。在交叉特征高度稀疏的情况下,参数仍然能够估计。
因为交叉特征的参数不仅仅依赖于这个交叉特征,还依赖于所有相关的交叉特征。这相当于增强了有效的学习数据。
能够泛化到未被观察到的交叉特征。
设交叉特征
“看过电影 A 且 年龄等于20”从未在训练集中出现,但出现了“看过电影 A”相关的交叉特征、以及“年龄等于20”相关的交叉特征。于是可以从这些交叉特征中分别学习
“看过电影 A”的representation、“年龄等于20”的 ,最终泛化到这个未被观察到的交叉特征。
3.2 ALS 优化算法
3.2.1 最优化解
FM的目标函数最优化可以直接采用随机梯度下降SGD算法求解,但是采用SGD有个严重的问题:需要选择一个合适的学习率。学习率必须足够大,从而使得
SGD能够尽快的收敛。学习率太小则收敛速度太慢。学习率必须足够小,从而使得梯度下降的方向尽可能朝着极小值的方向。
由于
SGD计算的梯度是真实梯度的估计值,引入了噪音。较大的学习率会放大噪音的影响,使得前进的方向不再是极小值的方向。
论文提出了一种新的交替最小二乘
alternating least square:ALS算法来求解FM目标函数的最优化问题。与
SGD相比ALS优点在于无需设定学习率,因此调参过程更简单。根据定义:

对每个 ,可以将
 分解为 的线性部分和偏置部分:
分解为 的线性部分和偏置部分:
其中 与
 无关。如:
无关。如:对于 有:

对于 有:

对于 有:

因此有:
考虑均方误差损失函数:

最小值点的偏导数为 0 ,有:
则有:

ALS通过多轮次、轮流迭代求解 即可得到模型的最优解。在迭代之前初始化参数,其中:
 通过零初始化, 的每个元素通过均值为0、方差为
通过零初始化, 的每个元素通过均值为0、方差为  的正太分布随机初始化。
的正太分布随机初始化。每一轮迭代时:
首先求解 ,因为相对于二阶交叉的高阶特征,低阶特征有更多的数据来估计其参数,因此参数估计更可靠。
然后求解
。这里按照维度优先的准确来估计:先估计所有 representation向量的第1维度,然后是第2维,… 最后是第d维。这是为了计算优化的考量。
3.2.2 计算优化
直接求解
ALS的解时复杂度较高:在每个迭代步中计算每个训练样本的 和 。
。对于每个样本,求解 和
的计算复杂度为:- 计算 的复杂度为
 ,计算 的复杂度为
,计算 的复杂度为 - 计算 的复杂度为 ,计算 的复杂度为
- 计算 的复杂度为
 ,计算 的复杂度为
,计算 的复杂度为 
因此求解 的计算复杂度为
 。
。- 计算 的复杂度为
有三种策略来降低求解 的计算复杂度,从
降低到 ,其中  表示平均非零特征的数量:
表示平均非零特征的数量:- 利用预计算的 项降低交叉特征的
 的计算代价。
的计算代价。 - 利用数据集 的稀疏性降低整体计算代价。
- 利用预计算的 项降低交叉特征的
预计算误差项
 :
:定义误差项:
考虑到 ,则有:

因此如果计算 的计算代价较低,则计算
 的计算复杂度也会降低。
的计算复杂度也会降低。首先对每个样本,计算其初始误差:
考虑到
的计算复杂度为 ,因此  的计算复杂度为 。
的计算复杂度为 。当参数
 更新到 时,重新计算误差:
更新到 时,重新计算误差:
计算代价由 决定 (根据下面的讨论,其计算复杂度为
)。
预计算 值:
如果能够降低计算
的代价,则整体计算复杂度可以进一步降低。由于 的复杂度为 ,因此重点考虑 的计算复杂度。重写
 ,有:
,有:定义:

因此如果计算 的计算代价较低,则
 的计算复杂度也会降低。
的计算复杂度也会降低。对每个样本、每个
representation向量维度计算初始 值:
计算复杂度为 。
当参数
 更新到 时,重新
更新到 时,重新  值:
值:计算代价为
。一旦得到 ,则有:

计算代价为
数据集
的稀疏性:根据:
对于
 ,其计算复杂度为
,其计算复杂度为 
对于 , 我们只需要迭代
中 的样本,即  的样本。
的样本。因此每次更新只需要使用部分样本。总体而言,整体复杂度为 ,其中
表示平均非零特征的数量。
3.2.3 算法
ALS优化算法:输入:
- 训练样本
- 随机初始化的方差
输出:模型参数

算法步骤:
参数初始化:
初始化
 :
:迭代直至目标函数收敛或者达到指定步数,每一轮迭代过程为:
更新
:更新
 :
:更新
 :
:外层循环为 ,内层循环为
。这是为了充分利用 。
论文实验给出了
SGD和ALS优化算法的比较结果。可以看到:SGD的优化效果很大程度上取决于学习率和迭代次数。当精心挑选合适的学习率、足够大的迭代次数(根据验证集执行早停策略从而防止过拟合),
SGD可以达到 的效果。ALS不需要精心的、耗时的搜索合适的学习率,就可以达到很好的效果。

