
-
将有标记样本所对应的结点视作为已经染色,而未标记样本所对应的结点尚未染色。于是半监督学习就对应于“颜色”在图上扩散或者传播的过程。这就是标记传播算法 。
给定标记样本集 ,和未标记样本集
 ,其中 。
,其中 。基于
 构建一个图 。其中
构建一个图 。其中结点集

边集 的权重可以表示为一个亲和矩阵
affinity matirx ,一般基于高斯函数,其定义为:
,一般基于高斯函数,其定义为:其中
 是用户指定的高斯函数带宽参数。
是用户指定的高斯函数带宽参数。可以看到:
- ,因此
 为对称矩阵。
为对称矩阵。 - 图 是全连接的,任意两点之间都存在边。
- 两个点的距离越近,说明两个样本越相似,则边的权重越大;距离越远,说明两个样本越不相似,则边的权重越小。
- 权重越大说明样本越相似,则标签越容易传播。
- ,因此
3.1.1 能量函数
假定从图
 学得一个实值函数 , 其对应的分类规则为:
学得一个实值函数 , 其对应的分类规则为:  。
。直观上看,相似的样本应该具有相似的标记,于是可以定义关于 的能量函数
energy function:
两个点距离越远, 平方级的增大,而
 指数级下降,因此 下降。
指数级下降,因此 下降。因此能量函数
 由距离较近的样本对决定。
由距离较近的样本对决定。标签传播算法假定系统能量最小,即 最小。
考虑到
由距离较近的样本对决定,而 是已知的量,因此算法倾向于使得:距离较近的样本具有相近的输出 。
定义对角矩阵
 ,其中 为矩阵 的第 行元素之和。
,其中 为矩阵 的第 行元素之和。 的物理意义为:第 个顶点的度(所有与它相连的边的权重之和)。因此
的物理意义为:第 个顶点的度(所有与它相连的边的权重之和)。因此  也称作度矩阵。
也称作度矩阵。定义
 为函数 在所有样本上的预测结果。 其中:
为函数 在所有样本上的预测结果。 其中: 为函数 在有标记样本上的预测结果。
为函数 在有标记样本上的预测结果。 为函数 在未标记样本上的预测结果。
为函数 在未标记样本上的预测结果。
结合
的定义以及 的对称性,有:
标签传播算法将样本 的标记
 视作能量。
视作能量。有标记样本的能量是已知的,未标记样本的能量是未知的。
能量在样本之间流动。对于样本 ,它流向样本
 的能量为 。
的能量为 。- 表示边的权重,它就是能量流出的比例(类比于管道的大小)。
- 流出的能量可正可负,因为 。
- 注意:能量不能在有标记样本与有标记样本之间流动,也不能从未标记样本流向有标记样本。
流经每个未标记样本的能量是守恒的。对未标记样本
 :
:- 其能量流向其它的所有未标记结点,能量流出为: 。
- 其它所有结点(包括有标记样本)都向其汇入能量,能量流入为:
 。
。
考虑到 ,以及
 ,则有: 。 考虑所有的未标记样本,则有:
,则有: 。 考虑所有的未标记样本,则有:
从每个有标记样本流出的能量也是守恒的。对于有标记样本 ,它仅仅流出到未标记样本,因此流出能量为:
 。
。由于有标记样本只有能量流出,没有能量流入,因此有: 。
综合两种能量守恒的情况,有:

即有: 。
标签传播算法假定在满足约束条件的条件下,能量函数
最低。其中约束条件为:- 标记约束:函数 在标记样本上满足
 。
。 - 能量守恒:定义拉普拉斯矩阵 ,则有:

因此标签传播算法就是求解约束最优化问题:
.
- 标记约束:函数 在标记样本上满足
3.1.2 最优化求解
以第
 行第 列为界,采用分块矩阵表示方式:
行第 列为界,采用分块矩阵表示方式:
则:
考虑到
 是已知的,因此 完全由
是已知的,因此 完全由  决定。为求得 的最小值,则根据
决定。为求得 的最小值,则根据  有:
有:令:

令: ,则有:

于是,将 上的标记信息作为
 代入上式,即可求得未标记样本的预测值 。
代入上式,即可求得未标记样本的预测值 。 矩阵其实为概率转移矩阵:
矩阵其实为概率转移矩阵:它表示从节点
 转移到节点 的概率。
转移到节点 的概率。注意到
 ,因此 不是对称的。即:
,因此 不是对称的。即:节点 i 转移到节点 j 的概率不等于节点i 转移到节点 j 的概率。因此在Label Spreading算法中,提出新的标记传播矩阵 :
:因此有:
 ,
,节点 i 转移到节点 j 的概率等于节点i 转移到节点 j 的概率。此时的转移概率是非归一化的概率。矩阵求逆 的算法复杂度是
 。如果未标记样本的数量 很大,则求逆的过程非常耗时。这时一般选择迭代算法来实现。
。如果未标记样本的数量 很大,则求逆的过程非常耗时。这时一般选择迭代算法来实现。首先执行初始化:
 。
。迭代过程:
- 执行标签传播: 。
- 重置
 中的标签样本标记: 。
中的标签样本标记: 。
给定标记样本集
 ,和未标记样本集 ,其中
,和未标记样本集 ,其中  。
。与二类标签传播算法一样,首先基于 构建一个图
,然后定义边的权重矩阵 和度矩阵 。令 的标记向量为
 , 其中 表示
, 其中 表示  属于类别 的概率。根据概率的定义有:
属于类别 的概率。根据概率的定义有:
对于标记样本 ,
 中只有一个值为1 ,其他值为 0。设 的标记为
中只有一个值为1 ,其他值为 0。设 的标记为  ,即有:
,即有:对于未标记样本
, 表示一个概率分布,依次是该样本属于各个类别的概率。
当给定
的标记向量 时,样本的分类规则为:
其中 表示模型对样本
的预测输出。定义非负的标记矩阵为:

即: 的每一行代表每个样本属于各类别的概率。因此
 也称为软标记
也称为软标记soft label矩阵。定义非负的常量矩阵 为:

即: 的前
行就是 个有标记样本的标记向量。后  行全为 0 。
行全为 0 。
3.2.1 Label Propagation
Label Propagation算法通过节点之间的边来传播标记,边的权重越大则表示两个节点越相似,则标记越容易传播。定义概率转移矩阵 ,其中:

它表示标签从结点 转移到结点
 的概率。
的概率。定义标记矩阵 ,其中:

即:若 ,则第
行的第 个元素为1,该行其他元素都是 0。定义未标记矩阵
 ,矩阵的第 行为样本
,矩阵的第 行为样本  属于各标签的概率。
属于各标签的概率。合并 和
 即可得到 。
即可得到 。
Label Propagation是个迭代算法。算法流程为:首先执行初始化:
 。
。迭代过程:
- 执行标签传播: 。
- 重置 中的标签样本标记: ,其中
 表示 的前 行。
表示 的前 行。
Label Propatation算法:输入:
- 有标记样本集
- 未标记样本集

- 构图参数
输出:未标记样本的预测结果

-
基于
构造概率转移矩阵 。 其中  , 为矩阵 的第 行元素之和。
, 为矩阵 的第 行元素之和。构造非负的常量矩阵
 :
:初始化
 :
:初始化

迭代,迭代终止条件是 收敛至
 。 迭代过程为:
。 迭代过程为: ,其中 表示 的前 行。
,其中 表示 的前 行。
- 构造未标记样本的预测结果:
- 输出结果

3.2.2 Label Spreading
Label Spreading算法也是个迭代算法:首先初始化 为:
,其中 表示第 0 次迭代。然后迭代:
 。其中:
。其中:为标记传播矩阵
,其中 。 为用户指定的参数,用于对标记传播项 和初始化项
为用户指定的参数,用于对标记传播项 和初始化项  的重要性进行折中。
的重要性进行折中。- ,则每次迭代时尽可能保留初始化项 。最终数据集的分布与初始化项 非常相近。
 ,则每次迭代时尽可能不考虑 。最终数据集的分布与 差距较大。
,则每次迭代时尽可能不考虑 。最终数据集的分布与 差距较大。
- ,则每次迭代时尽可能保留初始化项
迭代直至收敛,可以得到: 。于是可以从
中可以获取 中样本的标记。由于引入
 ,因此
,因此 Label Spreading最终收敛的结果中,标记样本的标签可能会发生改变。这在一定程度上能对抗噪音的影响。如: 意味着有 80% 的初始标记样本的标签会保留下来,有 20% 的初始标记样本的标签发生改变。
Label Spreading算法:输入:
- 有标记样本集
- 未标记样本集
构图参数

折中参数
- 有标记样本集
输出:未标记样本的预测结果
步骤:
- 根据下式,计算 :

基于 构造标记传播矩阵
。 其中 , 为矩阵 的第 行元素之和。
为矩阵 的第 行元素之和。构造非负的常量矩阵 :

初始化 :
初始化
迭代,迭代终止条件是
收敛至 。 迭代过程为:- 构造未标记样本的预测结果:

- 输出结果
其实上述算法都对应于正则化框架:

其中:
- 为正则化参数 。当
 时,上式的最优解恰好为
时,上式的最优解恰好为 - 上式第二项:迫使学得结果在有标记样本上的预测与真实标记尽可能相同。
- 上式第一项:迫使相近样本具有相似的标记。
这里的标记既可以是离散的类别,也可以是连续的值。
- 为正则化参数 。当
虽然二类标签传播算法和多类标签传播算法理论上都收敛,而且都知道解析解。但是:
- 对二类标签传播算法,矩阵求逆
 的算法复杂度是 。如果未标记样本的数量 很大,则求逆的过程非常耗时。
的算法复杂度是 。如果未标记样本的数量 很大,则求逆的过程非常耗时。 - 对多类标签传播算法,矩阵求逆 的算法复杂度是
 。如果样本总数量 很大,则求逆的过程非常耗时。
。如果样本总数量 很大,则求逆的过程非常耗时。
因此标签传播算法一般选择迭代算法来实现。
- 对二类标签传播算法,矩阵求逆
图半监督学习方法在概念上相当清晰,且易于通过对所涉及矩阵运算的分析来探索算法性质。
缺点:
- 在存储开销上较大,使得此类算法很难直接处理大规模数据。
- 由于构图过程仅能考虑训练样本集,难以判断新的样本在图中的位置。因此在接收到新样本时,要么将其加入原数据集对图进行重构并重新进行标记传播,要么引入额外的预测机制。
PageRank算法用于对网页进行排名。它也是利用能量在有向图 中的流动来获得网页的重要性得分。每个网页代表图 中的一个顶点,所有顶点的集合为
 。
。如果存在超链接,该超链接从顶点 对应的网页指向顶点
对应的网页,则存在一条有向边从顶点 指向顶点 。所有的边的集合为 。
每个顶点都存储有能量,能量对应着网页的重要性得分。
对每个网页,设其能量为
 :
:用户以概率 选择一个超链接,进入下一个网页。这意味着有
 的能量从当前顶点流失,流向下一个网页。
的能量从当前顶点流失,流向下一个网页。用户以概率 随机选择一个网页。这意味着有
 的能量从当前顶点流失,流向全局能量池。同时有 的能量流入当前顶点,其中
的能量从当前顶点流失,流向全局能量池。同时有 的能量流入当前顶点,其中  是系统中所有顶点的总能量, 为顶点数量。
是系统中所有顶点的总能量, 为顶点数量。这是因为每个顶点都有
 比例的能量流入全局能量池,则全局能量池的流入能量为 。而全局能量池的能量又平均流入到每个顶点中,则每个顶点从全局能量池得到的能量为
比例的能量流入全局能量池,则全局能量池的流入能量为 。而全局能量池的能量又平均流入到每个顶点中,则每个顶点从全局能量池得到的能量为  。
。
当系统取得平衡时,满足以下条件:
- 全局能量池的流入、流出能量守恒。
- 每个顶点的流入、流出能量守恒。
- 系统所有顶点的总能量为常数。
假设
 ,即系统所有顶点的总能量恒定为 1 。对给定的顶点 ,假设其能量为
,即系统所有顶点的总能量恒定为 1 。对给定的顶点 ,假设其能量为  。
。- 流出能量为: 。
- 流入能量为:
 。其中 为能量从顶点 流向顶点 的概率。
。其中 为能量从顶点 流向顶点 的概率。
则顶点
的净入能量为: 。考虑所有顶点,令
 , ,
, , ,则系统每个顶点净流入能量组成的向量为:
,则系统每个顶点净流入能量组成的向量为:当系统稳定时,每个顶点的净流入能量为 0 。因此有:
 。
。考虑到所有顶点的总能量恒定为 1,则有 。
定义矩阵
 为:
为:则有:
 。因此有: 。
。因此有: 。令
 ,则有 。此时的
,则有 。此时的  就是对应于 的特征值为 1 的特征向量(经过归一化使得满足的总能量恒定为 1)。
就是对应于 的特征值为 1 的特征向量(经过归一化使得满足的总能量恒定为 1)。
设图
,社区发现就是在图 中确定  个社区 ,其中满足
个社区 ,其中满足  。
。若任意两个社区的顶点集合的交集均为空,则称 为非重叠社区,此时等价于聚类。否则称作重叠社区,此时一个顶点可能从属于多个社区。
社区划分的好坏是通过考察当前图的社区划分,与随机图的社区划分的差异来衡量的。
当前图的社区划分:计算当前图的社区结构中,内部顶点的边占所有边的比例 :
 。
。其中:
表示顶点
与顶点 之间的边的权重,  表示图 中所有边的权重之和
表示图 中所有边的权重之和  。
。表示顶点
所属的社区, 表示顶点 所属的社区。 函数定义为:
因为 ,因此每条边被计算了两次,所以系数为
 。
。
它可以简化为:,其中
 表示社区 中所有内部边的总权重。
表示社区 中所有内部边的总权重。随机图的社区划分:计算随机图的社区结构中,内部顶点的边占所有边的比例的期望。
随机图是这样生成的:每个顶点的度保持不变,边重新连接。
记顶点
和 之间的边的期望权重为  ,则它满足下列条件:
,则它满足下列条件:- 因为每个顶点的度不变,则最终总度数不变。即: 。
- 对每个顶点,它的度保持不变。即:
 。其中 表示顶点 的度。
。其中 表示顶点 的度。 - 随机连边时,一个边的两个顶点的选择都是独立、随机的。因此对于 ,选到 的概率与 有关,选到 的概率与 有关。根据独立性有:
 ,其中 为某个映射函数。
,其中 为某个映射函数。
根据
,以及 有: 。
。由于 不包含
,因此 与 是倍乘关系。不妨假设 ,其中  为常量。则有:
为常量。则有:考虑到
 ,则有: 。因此有:
,则有: 。因此有:
因此有: 。
因此随机图的社区结构中,内部顶点的边占所有边的比例的期望为:

3.5.1 Fast Unfolding
Fast Unfolding算法是基于modularity的社区划分算法。它是一种迭代算法,每一步3迭代的目标是:使得划分后整个网络的 不断增大。
Fast Unfolding算法主要包括两个阶段:第一阶段称作
modularity optimization:将每个顶点划分到与其邻接的顶点所在的社区中,以使得modularity不断增大。考虑顶点 ,设其邻接顶点
位于社区 中。未划分之前,顶点
是一个独立的社区,它对 的贡献为: 。因为该社区只有一个顶点,因此所有顶点的度之和就是 。
。因为该社区只有一个顶点,因此所有顶点的度之和就是 。未划分之前,社区
 对于 的贡献为:
对于 的贡献为: 。
。划分之后,除了社区 与顶点
之外,所有社区、顶点在划分前后保持不变,因此 的变化为:
其中 分别表示划分之后社区
的所有内部边的总权重、所有顶点的度之和。
设顶点 与社区
相连的边的度数之和为 (可能 有多条边与 相连) ,则有: 。
。由于顶点 现在成为社区
的内部顶点,因此 。因此有:

- 如果 ,则将顶点 划入到社区 中。
- 如果
 ,则顶点 保持不变。
,则顶点 保持不变。
- 第二阶段称作
modularity Aggregation:将第一阶段划分出来的社区聚合成一个点,这相当于重新构造网络。
重复上述过程,直到网络中的结构不再改变为止。
Fast Unfolding算法:输入:
- 数据集

- 数据集
输出:社区划分 。
算法步骤:
构建图:根据
 构建图 。
构建图 。初始化社区:构建
 个社区,将每个顶点划分到不同的社区中。
个社区,将每个顶点划分到不同的社区中。此时每个社区有且仅有一个顶点。
迭代,迭代停止条件为:图保持不变 。迭代步骤为:
遍历每个顶点:
随机选择与其相连的顶点的社区,考察 。如果
 ,则将该顶点划入到该社区中;否则保持不变。
,则将该顶点划入到该社区中;否则保持不变。重复上述过程,直到不能再增大
modularity为止。构造新的图:将旧图中每个社区合并为新图中的每个顶点,旧社区之间的边的总权重合并为新图中的边的权重。
然后重复执行上述两步。
对于顶点 ,在考察
 时,可以遍历与其相连的所有顶点所属的社区,然后选择最大的那个 。
时,可以遍历与其相连的所有顶点所属的社区,然后选择最大的那个 。上述算法是串行执行:逐个选择顶点,重新计算其社区。在这个过程中其它顶点是不能变化的。
事实上可以将其改造为并行算法,在每一步迭代中同时更新多个顶点的信息。
Fast Unfolding算法的结果比较理想,对比LPA算法会更稳定。另外Fast Unfolding算法不断合并顶点并构造新图,这会大大减少计算量。
3.5.2 LPA
Usha等人于2007年首次将标签传播算法用于社区发现。不同于半监督学习,在社区发现中并没有任何样本的标注信息,这使得算法不稳定,可能得到多个不同的社区划分结果。
标签传播算法在迭代过程中,对于顶点
,会根据它的邻居顶点更新 的社区。更新规则为: 的邻居顶点中,哪个社区出现最多,则顶点 就属于哪个社区。如果多个社区出现的次数都是最多的,则随机选择一个。
标签传播算法:
输入:
- 数据集
- 数据集
输出:社区划分 。
算法步骤:
构建图:根据
构建图 。初始化:为每个顶点指定一个唯一的标签。
迭代,迭代停止条件为社区划分收敛。迭代步骤为:
随机打乱顶点的顺序。
遍历每个顶点
,设置顶点 的标签为:
其中 表示顶点
的邻居顶点集合, 表示顶点 的标签, 表示示性函数。判断是否收敛。收敛条件为:遍历每个顶点
,满足:即:顶点
的邻居顶点集合中,标签为 的点的个数最多。之所以取
=是因为:可能出现个数一样多的情况,这时也是满足条件的。
标签传播算法的优点是:简单、高效、快速。缺点是每次迭代结果不稳定,准确率不高。
标签传播算法中,顶点的标签有同步更新和异步更新两种方式。
同步更新(假设更新次数为
 ):
):同步更新方法在二分图中可能出现震荡的情况,如下图所示。
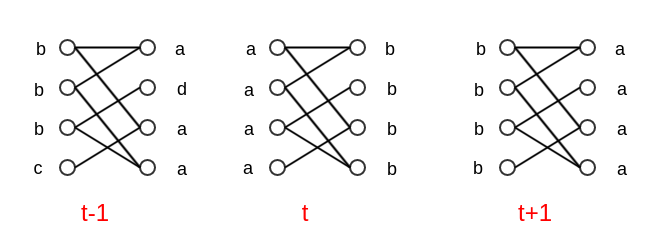
异步更新:
 为顶点 的最新的标签值。如果它最近的更新是在第
为顶点 的最新的标签值。如果它最近的更新是在第  轮,则 ;如果它最近的更新是在第 轮,则 。
轮,则 ;如果它最近的更新是在第 轮,则 。异步更新可以保证收敛,因此标签传播算法采用异步的策略更新顶点的标签,并在每次迭代之前对顶点重新进行随机排序从而保证顶点是随机遍历的。
标签传播算法的时间复杂度为
 ,空间复杂度为 。因此标签传播算法具有线性的时间复杂度并且可以很好地适应大规模社区的检测。
,空间复杂度为 。因此标签传播算法具有线性的时间复杂度并且可以很好地适应大规模社区的检测。它既不需优化预定义的目标函数,也不需要关于社区的数量和规模等先验信息。
3.5.3 SLPA
SLPA由Jierui Xie等人于 2011 年提出,它是一种重叠型社区发现算法。通过设定参数,也可以退化为非重叠型社区发现算法。SLPA与LPA的重要区别:SLPA引入Listener和Speaker的概念。其中Listener就是待更新标签的顶点, 就是该顶点的邻居顶点集合。在
LPA中,Listener的标签由Speaker中出现最多的标签决定。而SLPA中引入了更多的规则。SLPA会记录每个顶点的历史标签序列。假设更新了 次,则每个顶点会保存一个长度为 的序列。当迭代停止之后,对每个顶点的历史标签序列中各标签出现的频率作出统计,按照某一给定的阈值
 过滤掉那些频率小的标签,剩下的就是该顶点的标签,通常会有多个标签。
过滤掉那些频率小的标签,剩下的就是该顶点的标签,通常会有多个标签。
SLPA算法:输入:
- 数据集
- 迭代步数
- 标签频率阈值
Speaker ruleListener rule
输出:社区划分
 。
。算法步骤:
构建图:根据 构建图
。初始化:为每个顶点分配一个标签队列;为每个顶点指定一个唯一的标签,并将标签加入到该顶点的标签队列中。
迭代 步。迭代步骤为:
随机打乱顶点的顺序。
遍历每个顶点
,将顶点 设置为Listener, 将顶点 的邻居顶点都设置为Speaker。Speaker根据Speaker rule向Listener发送消息。Speaker rule为发送规则,如:Speaker从它的标签队列中发送最新的标签、或者Speaker从它的标签队列中随机选择一个标签发送(标签选择的概率等于标签队列中各标签出现的频率)。Listener接收消息,并根据Listener rule更新标签,并将最新的标签加入到它的标签队列中。Listener rule为接收规则。如: 选择接受的标签中出现最多的那个作为最新的标签。

