
-
n_neighbors:一个整数,指定近邻参数 。n_components:一个整数,指定降维后的维数。reg:一个浮点数,指定正则化项的系数。eigen_solver:一个字符串,指定求解特征值的算法,可以为:'auto':由算法自动选取。'arpack':使用Arnoldi分解算法。'dense':使用一个直接求解特征值的算法(如LAPACK)。
tol:一个浮点数,指定求解特征值算法的收敛阈值(当eigen_solver='dense'时,该参数无用)。max_iter:一个浮点数,指定求解特征值算法的最大迭代次数(当eigen_solver='dense'时,该参数无用)。-
- :使用标准的
LLE算法。 'modified':使用modified LLE算法。'ltsa':使用local tangent space alignment算法。
- :使用标准的
hessian_tol:一个浮点数,用于method='hessian'时收敛的阈值。modified_tol:一个浮点数,用于method='modified'时收敛的阈值。neighbors_algorithm:一字符串,指定计算最近邻的算法。可以为:'ball_tree':使用BallTree算法。'kd_tree:使用KDTree算法。'brute':使用暴力搜索法。- :自动决定最合适的算法。
random_state:一个整数或者一个RandomState实例,或者None,指定随机数种子。它用于
eigen_solver='arpack'。
属性:
embedding_vectors_:给出了原始数据在低维空间的嵌入矩阵。
-
fit(X[, y]):训练模型。transform(X):执行降维,返回降维后的样本集。fit_transform(X[, y]):训练模型并执行降维,返回降维后的样本集。
示例:鸢尾花数据集分别降低到4、3、2、1 维时,重构误差分别为:
reconstruction_error(n_components=4) : 7.19936880176e-07reconstruction_error(n_components=3) : 3.8706050149e-07reconstruction_error(n_components=2) : 6.64141991211e-08reconstruction_error(n_components=1) : -1.74047846991e-15
该指标并不能用于判定降维的效果的好坏,它只是一个中性指标。
不同的
k降维到2维后的样本的分布图如下所示。可以看到 时,近邻范围过小,同样发生了断路现象。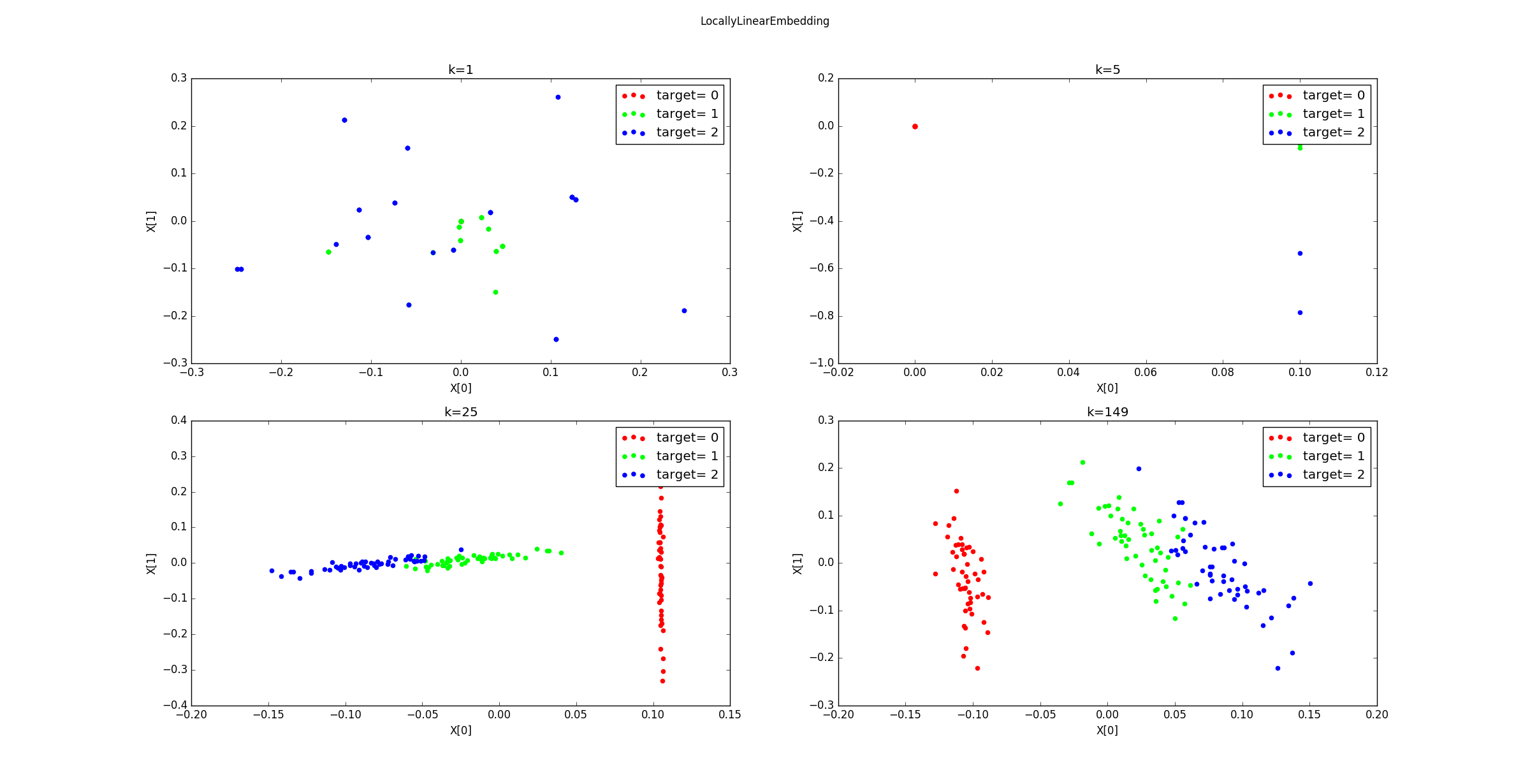
不同的
k降维到1维后的样本的分布图如下所示。
四、LocallyLinearEmbedding
本文档使用 BookStack 构建

