
-
把离散特征
one-hot编码,设各binary特征分别记作:male,female,age18,age19,age20,bj,sh,gz,sz,y表示样本标签(-1表示不感兴趣,+1表示感兴趣)。记作:
POLY2模型为:
参数个数为 ,计算复杂度为
 。
。FM模型为:参数个数为
 ,计算复杂度为 。
,计算复杂度为 。FM要优于POLY2,原因是:交叉特征非零的样本过于稀疏使得无法很好的估计 ;但是在
;但是在 FM中,交叉特征的参数可以从很多其它交叉特征中学习,使得参数估计更准确。如:交叉特征 从未出现过,因此在
POLY2模型中参数 根本无法学习。
根本无法学习。而在
FM模型中male=1的representation向量可以从以下交叉特征的样本中学习:age19=1的representation向量可以从交叉特征 的样本中学习。
的样本中学习。另外
FM还可以泛化到没有见过的交叉特征。如:交叉特征 从未在训练样本中出现过,但是在预测阶段
FM模型能够较好的预测该交叉特征的测试样本。
在
FM模型中,每个特征的representation向量只有一个。如:计算 用到的是同一个向量 。
用到的是同一个向量 。论文
Field-aware Factorization Machines for CTR Prediction提出的FFM算法认为:age=18和sh=1之间的区别,远远大于age=18和age=20之间的区别。因此,
FFM算法将特征划分为不同的域field。其中:- 特征
 属于性别域
属于性别域 gender field。 - 特征 属于年龄域
age field。 - 特征
 属于城市域
属于城市域 city field。
FFM中每个特征的representation向量有多个,用于捕捉该特征在不同field中的含义。如:特征
male=1具有两个representation向量:- 当用于计算
age field域的交叉特征时,采用 - 当用于计算
city field域的交叉特征时,采用
其它特征依次类推。
注意:
male=1没有gender field域的交叉特征。因为one-hot编码的原因 ,交叉特征male=1,female=1一定不能同时存在,所以不用计算 。- 特征
FFM模型用数学语言描述为:
其中: 表示第
 个特征所属的
个特征所属的 field,一共有 个field( )。
)。参数数量为 ,计算复杂度为
 ,其中 是样本中平均非零特征数。
,其中 是样本中平均非零特征数。和
FM相比,通常FFM中representation向量的维度要低的多。即:
FFM每个representation向量的学习只需要特定field中的样本。如:学习 时,只需要考虑交叉特征
 的样本,而不需要考虑交叉特征 的样本。
的样本,而不需要考虑交叉特征 的样本。和
FM相同,FFM模型也可以用于求解分类问题(预测各评级的概率),也可以用于求解回归问题(预测各评分大小)。对于回归问题,其损失函数为 均方误差:

对于二分类问题(分类标签为
-1,+1),其损失函数为交叉熵:.
FFM模型采用随机梯度下降算法来求解,使用AdaGrad优化算法。在每个迭代步随机采样一个样本
 来更新参数,则 退化为:
来更新参数,则 退化为:统一所有的
 ,则有:
,则有:其中:
 表示
表示field f内的所有特征; 表示:
对梯度的每个维度,计算累积平方:
其中
 是 的第 个分量, ;
是 的第 个分量, ; 是 的第
是 的第  个分量, 。
个分量, 。更新参数:

其中 是用户指定的学习率,
 。
。
模型参数需要合适的初始化。论文推荐:
- 从均匀分布
 中随机初始化
中随机初始化 - 初始值为1,这是为了防止在迭代开始时
 太大,从而导致前进方向较大的偏离损失函数降低的方向。
太大,从而导致前进方向较大的偏离损失函数降低的方向。
原始论文并没有 的项,因此个人推荐采用 零均值、方差为
 的正态分布来初始化它们。
的正态分布来初始化它们。- 从均匀分布
论文推荐采用样本级别的归一化,这可以提升模型泛化能力。
注:如果采用
Batch normalization效果可能会更好。论文未采用BN,是因为论文发表时BN技术还没有诞生。FFM的AdaGrad优化算法:输入:
- 训练集
- 学习率

- 最大迭代步
输出:极值点参数

算法步骤:
初始化参数和 :

迭代 步,每一步的过程为:
随机从
 中采样一个样本
中采样一个样本 计算
 :
:计算
 ,更新
,更新 遍历所有的项:
 :
:计算 ,更新

遍历所有的项:
- 计算

- 遍历所有的维度::计算
 ,并更新
,并更新
- 计算
FFM模型需要为每个特征分配一个field。离散型特征
categorical:通常对离散型特征进行one-hot编码,编码后的所有二元特征都属于同一个field。数值型特征
numuerical:数值型特征有两种处理方式:不做任何处理,简单的每个特征分配一个
field。此时
 ,
, FFM退化为POLY2模型。数值特征离散化之后,按照离散型特征分配
field。论文推荐采用这种方式,缺点是:
- 难以确定合适的离散化方式。如:多少个分桶?桶的边界如何确定?
- 离散化会丢失一些信息。
离散集合特征
categorical set(论文中也称作single-field特征):所有特征都属于同一个field,此时 ,FFM退化为FM模型。如
NLP情感分类任务中,特征就是单词序列。- 如果对整个
sentence赋一个field,则没有任何意义。 - 如果对每个
word赋一个field,则 等于词典大小,计算复杂度 无法接受。
等于词典大小,计算复杂度 无法接受。
- 如果对整个
实验效果的评估指标是负的对数似然,该指标越小越好:

其中 为训练集或者验证集的样本数。
-
超参数
 的实验效果如下图所示。
的实验效果如下图所示。第一列为不同 的取值(论文中用
k这个不同的符号),第二列为平均每个epoch的计算时间,第三列为验证集的logloss。可以看到:不同的
representation向量维度,对模型的预测能力影响不大,但是对计算代价影响较大。- 由于采用了
SSE指令集,所以 时每个
时每个 epoch计算时间几乎相同。 - 所以在
FFM中,通常选择一个较小的 值。

- 由于采用了
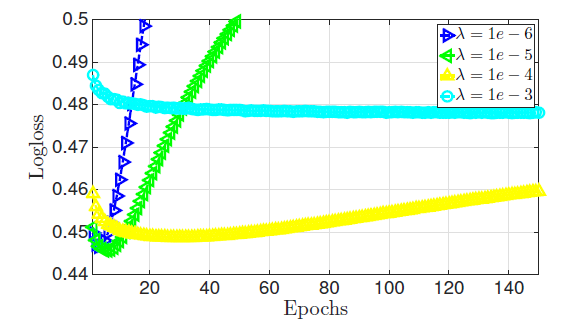
超参数 的实验效果如下图所示。
可以看到:
- 如果正则化系数太小,则模型太复杂,容易陷入过拟合。
- 如果正则化系数太大,则模型太简单,容易陷入欠拟合。
一个合适的正则化系数不大不小,需要精心挑选。
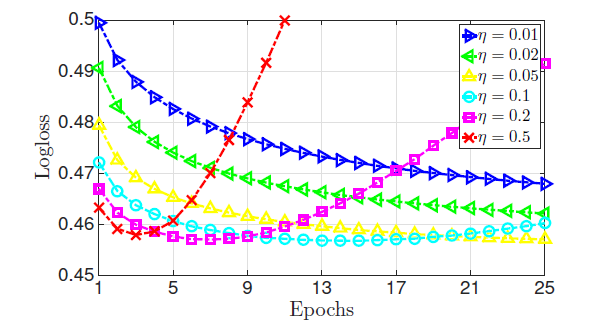
学习率 的实验效果如下图所示:
可以看到:
- 如果学习率较小,虽然模型可以获得一个较好的性能,但是收敛速度很慢。
- 如果学习率较大,则目标函数很快下降,但是目标函数不会收敛到一个较低的水平。
论文在
Criteo和Avazu数据集上比较了不同算法、不同优化方式、不同参数的结果。Criteo和Avazu数据集是Kaggle提供的,其中有两个测试集::当提交模型时,模型在该测试集上的得分和排名立即计算出来。
private test:当提交模型时,模型在该测试集上的得分和排名必须等竞赛结束时刻才揭晓。这是为了防止选手的模型对
public test过拟合。
论文选择了四种算法:
LM模型(线性模型)、POLY2模型、FM模型、FFM模型;选择了三种优化算法:SG(随机梯度下降)、CD(坐标下降)、Newton(牛顿法)、ALS;选择了不同参数。LIBFM支持SG,ALS,MCMC三种优化算法,但是论文发现ALS效果最好。因此这里LIBFM使用ALS优化算法。FM、FFM都是论文基于SG优化算法来实现的。同时对于SG优化算法采取早停策略。- 对于非
SG优化算法,停止条件由各算法给出合适的停止条件。
从实验结果可以看到:
FFM模型 效果最好,但是其训练时间要比LM和FM更长;LM效果比其它模型都差,但是它的训练要快得多;FM是一种较好的平衡了预测效果和训练速度的模型。因此这就是效果和速度的平衡。
POLY2比所有模型都慢,因为其计算代价太大。从两种
FM的优化方法可见,SG要比ALS优化算法训练得快得多。逻辑回归是凸优化问题,理论上
LM和POLY2的不同优化算法应该收敛到同一个点,但实验表明并非如此。原因是:我们并没有设置合适的停止条件,这使得训练过程并没有到达目标函数极值点就提前终止了。
论文比较了其它数据集上不同模型的表现。其中:
KDD2010-bridge,KDD2012,adult数据集包含数值特征和离散特征,论文将数值特征执行了离散化。cod-rna,ijcnn数据集仅仅包含数值特征 ,论文将数值特征进行两种处理从而形成对比:- 将数值特征离散化
- 每个数值特征作为一个
field(称作dummy fields)
phishing数据集仅仅包含离散特征。
实验结果表明:
FFM模型几乎在所有数据集上都占优。这些数据集的特点是:- 大多数特征都是离散的
- 经过
one-hot编码之后大多数特征都是稀疏的
在
phishing,adult数据集上FFM几乎没有优势。原因可能是:这两个数据集不是稀疏的,导致FFM,FM,POLY2这几个模型都具有几乎相同的表现。在
adult数据集上LM的表现和FFM,FM,POLY2几乎完全相同,这表明在该数据集上特征交叉几乎没有起到什么作用。在
dummy fields的两个数据集上FFM没有优势,说明field不包含任何有用的信息。在数值特征离散化之后,尽管
FFM比FM更有优势,但还是不如使用原始数值特征的FM模型。这说明数值特征的离散化会丢失一些信息。
从实验中总结的
FFM应用场景:- 数据集包含离散特征,且这些离散特征经过
one-hot编码。 - 经过编码后的数据集应该足够稀疏,否则
FFM无法获取较大收益(相对于FM)。 - 不应该在连续特征的数据集上应用
FFM,此时最好使用 。
- 数据集包含离散特征,且这些离散特征经过

