
-
利用顶点的文本信息的一个直接方法是:分别独立学习文本特征 和网络顶点
representation,然后将二者拼接在一起。这种方法没有考虑网络结构和文本信息之间的复杂交互,因此通常效果一般。论文
《Network Representation Learning with Rich Text Information》提出了text-associated DeepWalk:TADW模型,该模型在矩阵分解的框架下将顶点的文本信息纳入网络表示学习中。
给定网络 ,
NRL的目标是对每个顶点 得到一个低维表达 ,其中
得到一个低维表达 ,其中  。
。根据论文
《NeuralWord Embedding as Implicit Matrix Factorization》以及GraRep的结论,基于SGNS的DeepWalk等价于矩阵分解:其中:
 为转移概率矩阵, 为邻接矩阵,
为转移概率矩阵, 为邻接矩阵, 为度矩阵。
为度矩阵。定义了从顶点
 经过一步转移到顶点 的概率,因此也称为一阶转移概率矩阵。
经过一步转移到顶点 的概率,因此也称为一阶转移概率矩阵。 为 阶转移矩阵,
为 阶转移矩阵,  定义了顶点 经过
定义了顶点 经过  步转移到顶点 的概率。
步转移到顶点 的概率。 , 。
, 。 。
。
进一步的,基于该思路类似可以证明:基于
softmax的SkipGram模型等价于矩阵分解:定义矩阵
 ,则可以对 进行低秩分解:
,则可以对 进行低秩分解:  ,其中 , 。
,其中 , 。这个问题是
NP难的,因此研究者将这个问题转化为一个带约束的最优化问题:其中
 是 观察到的部分,
是 观察到的部分,  为
为 Frobenius范数, 为正则化系数。假设我们还有额外的特征,则可以使用
inductive matrix completion技术来利用这些额外特征。假设每个顶点还有额外的特征
 ,则可以进行矩阵分解:
,则可以进行矩阵分解:其中
 。
。目标函数为:
- 尽管优化算法最终收敛到局部极小值而不是全局极小值,但是经验表明
TADW效果较好。 - 这里的
 就是每个顶点的文本
就是每个顶点的文本representation矩阵,它是预训练好的。 - 最终我们拼接 和
 作为每个顶点的 维
作为每个顶点的 维 representation。
- 尽管优化算法最终收敛到局部极小值而不是全局极小值,但是经验表明
考虑到计算
 的计算复杂度为 ,因此
的计算复杂度为 ,因此TADW采用近似计算在速度和准确性之间折衷:
有两个好处:
- 计算复杂度降低到
算法复杂度:
计算
的复杂度为 。在最优化求解迭代过程中:
- 最小化一次
 的复杂度为
的复杂度为 - 最小化一次
 的复杂度为 。
的复杂度为 。
- 最小化一次
总的算法复杂度为
 。其中 为 中非零元素的数量。
。其中 为 中非零元素的数量。
4.2 实验
数据集:
Cora数据集:包含来自七个类别的2708篇机器学习论文。论文之间的链接代表引用关系,共有
5429个链接。从标题、摘要中生成短文本作为文档,并经过停用词处理、低频词处理(过滤文档词频低于 10个的单词),并将每个单词转化为
one-hot向量。最终每篇文档映射为一个
1433维的binary向量,每一位为0/1表示对应的单词是否存在。
Citeseer数据集:包含来自六个类别的3312篇公开发表出版物。文档之间的链接代表引用关系,共
4732个链接。从标题、摘要中生成短文本作为文档,并经过停用词处理、低频词处理(过滤文档词频低于 10个的单词),并将每个单词转化为
one-hot向量。最终每篇文档映射为一个
3703维的binary向量,每一位为 表示对应的单词是否存在。
Wiki数据集:包含来自十九个类别的2405篇维基百科文章。- 文章之间的链接代表超链接,共
17981个链接。我们移除了没有任何超链接的文档。 - 每篇文章都用内容单词的
TFIDF向量来表示,向量维度为4973维。
- 文章之间的链接代表超链接,共
其中
Cora、Citeseer数据集平均每篇文档包含18~32个单词,数据集被认为是有向图;Wiki数据集平均每篇文档包含 640 个单词,数据集被认为是无向图。评估方式:我们对抽取的
Graph Embedding分别采用线性SVM和TSVM来评估其监督学习和半监督学习的性能。评估方法是基于one-vs-rest来进行多分类任务。对于线性SVM我们分别随机选择10%~50%的样本作为训练集,剩下样本作为测试集;对于TSVM我们分别随机选择1%~10%的样本作为训练集,剩下样本作为测试集。我们评估测试集的分类
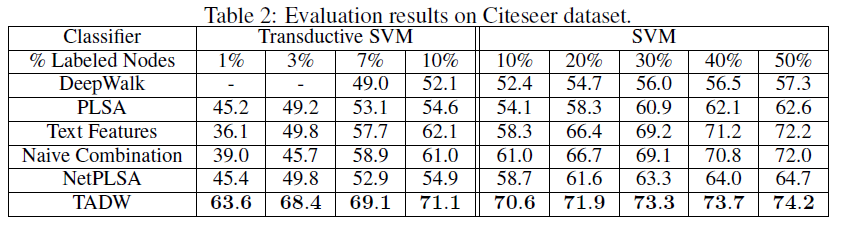
accuracy。每种拆分方式随机重复10次取均值作为结果。评估结果如下所示:
-表示TSVM训练12个小时都未收敛。我们并未在维基百科上给出半监督学习的结果。因为在该数据集上
TADW在监督学习的小数据集上已经证明其优越性,无需继续验证。结论:
TADW在所有三个数据集上始终优于其它所有模型。在
Cora,Citeseer数据集上,即使TADW模型的训练数据减少一半,其效果然仍然超过其它所有模型。这证明了TADW是有效的。TADW在半监督学习方面显著提升。在Cora数据集的半监督学习任务中,TADW超越了剩余的最佳模型4%;在Citeseer数据集的半监督学习任务中,TADW超越了剩余的最佳模型16%。这是因为
Citeseer数据集的噪声更大,而TADW对学习的噪声鲁棒性更好。当训练集较小时,
TADW效果更为明显。大多数模型的效果随着训练集比例的下降而迅速下降,因为这些模型的顶点
representation训练不充分,噪声较多。而TADW从网络和文本中共同学习的representation噪音更少。
固定训练集比例为
10%,我们评估超参数 (维度)和 (正则化系数)的影响。
(维度)和 (正则化系数)的影响。对于
Cora,Citeseer数据集 ;对于维基百科数据集 。
;对于维基百科数据集 。可以看到:
- 对于不同的数据集,最佳的维度 有所不同。
- 对于不同的数据集,最佳的维度

