
-
- 通常不能预先判断哪种类型的隐单元工作的最好,所以设计过程中需要反复试错,通过测试集评估其性能来选择合适的隐单元。
- 一般默认采用的隐单元是修正线性单元,但是仍然有许多其他类型的隐单元。
某些隐单元可能并不是在所有的输入上都是可微的。如:修正线性单元 在
 处不可微,这使得在该点处梯度失效。
处不可微,这使得在该点处梯度失效。事实上梯度下降法对这些隐单元的表现仍然足够好,原因是:
神经网络的训练算法通常并不会达到代价函数的局部最小值,而仅仅是显著地降低代价函数的值即可。
因此实际上训练过程中一般无法到达代价函数梯度为零的点,所以代价函数取最小值时梯度未定义是可以接受的。
不可微的点通常只是在有限的、少数的点上不可微,在这些不可微的点通常左导数、右导数都存在。
神经网络训练的软件实现通常返回左导数或者右导数其中的一个,而不是报告导数未定义或者产生一个错误。
这是因为计算机计算 0 点的导数时,由于数值误差的影响实际上不可能计算到理论上 0 点的导数,而是一个微小的偏离:向左侧偏离就是左导数,向右侧偏离就是右导数。
大多数隐单元的工作都可以描述为下面三步:
接受输入向量 。
计算仿射变换
 。
。用非线性函数 计算隐单元输出。
函数
 也称作激活函数,大多数隐单元的区别仅仅在于激活函数 的形式不同。
也称作激活函数,大多数隐单元的区别仅仅在于激活函数 的形式不同。
神经网络的隐层由多个隐单元组成,隐层的输出为:
 。
。
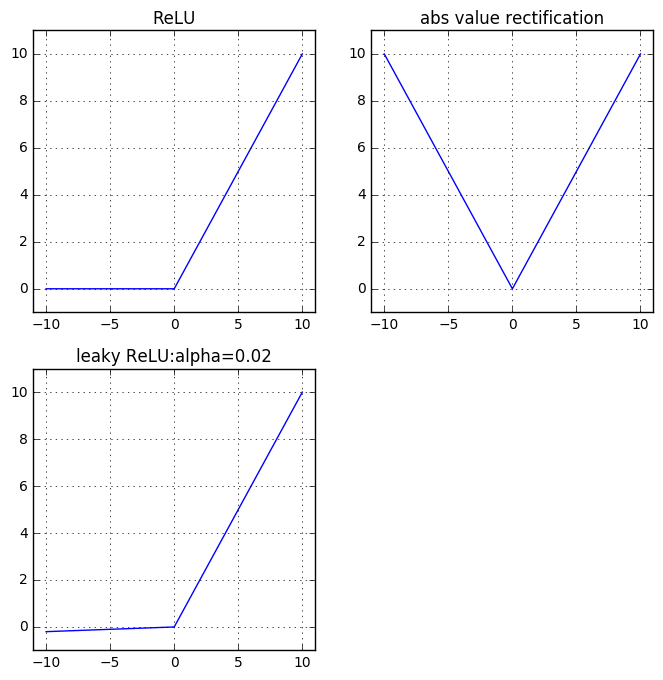
修正线性单元采用激活函数 ,它和线性单元非常类似,区别在于:修正线性单元在左侧的定义域上输出为零。
优点:采用基于梯度的优化算法时,非常易于优化。
当修正线性单元处于激活状态时,导数为常数 ;当修正线性单元处于非激活状态时,导数为常数
0。修正线性单元的二阶导数几乎处处为零。缺点:无法通过基于梯度的方法学习那些使得修正线性单元处于非激活状态的参数,因为此时梯度为零。
对于修正线性单元
 ,初始化时可以将 的所有元素设置成一个小的正值(如0.1),从而使得修正线性单元在初始时尽可能的对训练集中大多数输入呈现激活状态。
,初始化时可以将 的所有元素设置成一个小的正值(如0.1),从而使得修正线性单元在初始时尽可能的对训练集中大多数输入呈现激活状态。有许多修正线性单元的扩展存在,这些扩展保证了它们能在各个位置都保持非零的梯度。
大多数扩展的表现与修正线性单元相差无几,偶尔表现的更好。
修正线性单元的三个扩展:当
 时,使用一个非零的斜率 :
时,使用一个非零的斜率 :  。
。绝对值修正
absolute value rectification: 使用 ,此时 。
。渗透修正线性单元
leaky ReLU:将 固定成一个类似 0.01 的小值。
ReLU单元及其扩展都基于一个原则:越接近线性,则模型越容易优化。采用更容易优化的线性,这种一般化的原则也适用于除了深度前馈网络之外的网络。maxout单元是修正线性单元的进一步扩展。maxout单元并不是作用于 的每个元素 ,而是将 分成若干个小组,每个组有
,而是将 分成若干个小组,每个组有  个元素:
个元素:然后
maxout单元对每个组输出其中最大值的元素:
- 假设 是 100维的,
 ,则 为 5维的向量。
,则 为 5维的向量。 - 至于如何分组,则没有确定性的指导准则。
- 假设 是 100维的,
maxout单元的 通常是通过对输入 执行多个仿射变换而来。
通常是通过对输入 执行多个仿射变换而来。设
 ,
,maxout单元有 个分组,输出为 :
:令

则有: 。
maxout单元的优点:接近线性,模型易于优化。
经过
maxout层之后,输出维数降低到输入的 。这意味着下一层的权重参数的数量降低到
。这意味着下一层的权重参数的数量降低到maxout层的 。由多个分组驱动,因此具有一些冗余度来抵抗遗忘灾难
catastrophic forgetting。遗忘灾难指的是:网络忘记了如何执行它们过去已经训练了的任务。
在卷积神经网络中,
max pooling层就是由maxout单元组成。maxout单元提供了一种方法来学习输入空间中的多维度线性分段函数。它可以学习具有
段的线性分段的凸函数,因此maxout单元也可以视作学习激活函数本身。使用足够大的 ,
maxout单元能够以任意程度逼近任何凸函数。- 特别的,
 时的
时的maxout单元组成的隐层可以学习实现传统激活函数的隐层相同的功能,包括:ReLU函数、绝对值修正线性激活函数、leakly ReLU函数、参数化ReLU函数,也可以学习不同于这些函数的其他函数。 - 注意:
maxout层的参数化与ReLU层等等这些层不同(最典型的,层的输出向量的维数发生变化),因此即使maxout层实现了ReLU函数,其学习机制也不同。
- 特别的,
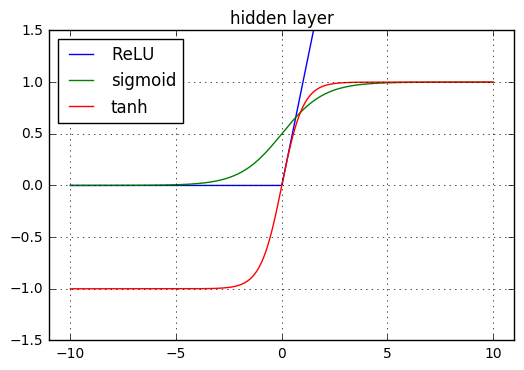
sigmoid单元和tanh单元:其激活函数分别为sigmoid函数和tanh函数。在引入修正线性单元之前,大多数神经网络使用
sigmoid函数 ,或者双曲正切函数 作为激活 函数。这两个激活函数密切相关,因为 。
作为激活 函数。这两个激活函数密切相关,因为 。与修正线性单元不同,
sigmoid单元和tanh单元在其大部分定义域内都饱和,仅仅当 在 0 附近才有一个较高的梯度,这会使得基于梯度的学习变得非常困难。因此,现在不鼓励将这两种单元用作深度前馈网络中的隐单元。
在 0 附近才有一个较高的梯度,这会使得基于梯度的学习变得非常困难。因此,现在不鼓励将这两种单元用作深度前馈网络中的隐单元。- 如果选择了一个合适的代价函数(如对数似然函数)来抵消了
sigmoid的饱和性,则这两种单元可以用作输出单元(而不是隐单元)。 - 如果必须选用
sigmoid激活函数时,tanh激活函数通常表现更佳。因为tanh函数在 0点附近近似于单位函数 。
- 如果选择了一个合适的代价函数(如对数似然函数)来抵消了
sigmoid激活函数在前馈网络之外的神经网络中更为常见。有一些网络不能使用修正线性单元,因此
sigmoid激活函数是个更好的选择,尽管它存在饱和问题。- 循环神经网络:修正线性单元会产生信息爆炸的问题。
- 一些概率模型:要求输出在
0~1之间。
存在许多其他种类的隐单元,但它们并不常用。经常会有研究提出一些新的激活函数,它们是前述的标准激活函数的变体,并表示它们表现得非常好。
除非这些新的激活函数被明确地证明能够显著地改进时,才会发布这些激活函数。如果仅仅与现有的激活函数性能大致相当,则不会引起大家的兴趣。
隐单元的设计仍然是个活跃的研究领域,许多有效的隐单元类型仍有待挖掘。
线性隐单元:它完全没有激活函数 ,也可以认为是使用单位函数
 作为激活函数 。
作为激活函数 。线性隐单元提供了一种减少网络中参数的数量的有效方法。
假设有一个隐层,它有 个输入,
 个输出,隐向量为 ,则
个输出,隐向量为 ,则  为 维的矩阵,需要
为 维的矩阵,需要  个参数。
个参数。可以用两层来代替该层:第一层使用权重矩阵 ,且没有激活函数;第二层使用权重矩阵
 ,且为常规激活函数。这对应了 的因式分解:
,且为常规激活函数。这对应了 的因式分解:  。
。假设第一层产生了 个输出,则有:第一层的输入为
 个,输出为 个;第二层的输入为
个,输出为 个;第二层的输入为  个,输出为 个。
个,输出为 个。整体参数为
 个。当 很小时,可以满足
个。当 很小时,可以满足  ,从而减少了参数。
,从而减少了参数。
softmax隐单元:激活函数为softmax函数。softmax单元既可以用作输出单元,也可以用作隐单元。softmax单元可以很自然地表示具有 个可能取值的离散型随机变量的概率分布,因此它也可以视作一种开关。
径向基函数隐单元:激活函数为径向基函数
RBF:
其中 表示权重矩阵的第
 列。
列。径向基函数在 接近
 时非常活跃,但是对于大部分 该函数值都饱和到 0,因此难以优化。
时非常活跃,但是对于大部分 该函数值都饱和到 0,因此难以优化。softplus隐单元:激活函数为softplus函数: 。这种单元是修正线性单元的平滑版本。
。这种单元是修正线性单元的平滑版本。通常不鼓励使用
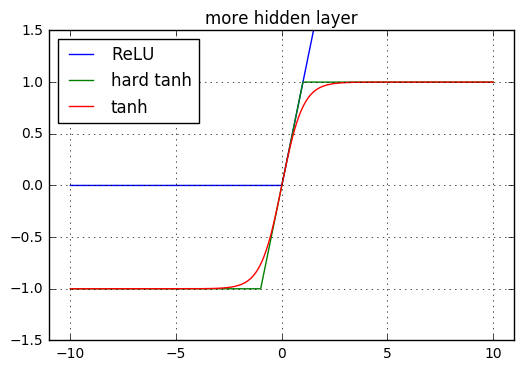
softplus激活函数,而推荐使用修正线性单元。理论上softplus函数处处可导,且它不完全饱和,所以人们希望它具有比修正线性单元更好的性能。但是根据经验来看,修正线性单元效果更好。硬双曲正切隐单元:激活函数为硬双曲正切函数:
 。
。它的形状和以及修正线性单元类似,但是它是有界的且在 点不可导。
sigmoid主要缺点:- 容易饱和从而使得梯度消失。当激活函数取值在接近0或者1时会饱和,此时梯度为近似为0。
- 函数输出不是零中心的。这会导致后续神经元的输出数值总是正数。
tanh:- 优点:函数输出是零中心的。
- 缺点:容易饱和从而使得梯度消失。
tanh激活函数几乎在所有场合都是优于sigmoid激活函数的。但是有一种情况例外:如果要求函数输出是0~1之间(比如表征某个概率),则二者之间必须用sigmoid。relu:优点:对随机梯度下降的收敛有巨大的加速作用,而且非常容易计算。
缺点:可能导致神经元死掉。
当一个很大的梯度流过
relu神经元时,可能导致梯度更新到一种特别的状态:在这种状态下神经元无法被其他任何数据点再次激活。此后流过这个神经元的梯度将变成 0,该单元在训练过程中不可逆的死亡。如果学习率设置的过高,可能会发现网络中大量神经元都会死掉。整个训练过程中,这些神经元都不会被激活。
leaky relu:为了解决relu死亡神经元的问题的尝试,但是效果并不明显。maxout: 它是relu和leaky relu的一般性归纳,以单输出的两段为例:当分成两段且
 时,就退化为单输出的
时,就退化为单输出的 relu激活函数。maxout单元拥有relu单元的所有优点,而没有它的缺点。maxout单元的缺点:对于 段的
maxout, 假设其输出为 维的,输出为 ,则有: 。
。相对于
relu单元 , 可以看到:maxout单元的参数数量增加到 倍。
在同一个网络中混合使用不同类型的激活函数非常少见,虽然没有什么根本性的问题来禁止这么做。
激活函数选取准则:
通常建议使用
relu激活函数。

