
-
基于频域卷积可以通过平滑约束实现近似的空间局部性,但是频域定义的卷积不是原生的空间局部性,并且频域卷积涉及到计算复杂度为 的矩阵乘法,其中
 为图中顶点数量。
为图中顶点数量。论文 提出了一种快速的、满足空间局部性的卷积核。这种卷积核有以下优点:
新卷积核与经典
CNN卷积核的计算复杂度相同,适用于所有的图结构。在评估阶段,其计算复杂度正比于卷积核的尺寸 核边的数量
 。由于真实世界的图几乎都是高度稀疏的,因此有 以及
。由于真实世界的图几乎都是高度稀疏的,因此有 以及  ,其中 为所有顶点的平均邻居数。
,其中 为所有顶点的平均邻居数。新卷积核具有严格的空间局部性,对于每个顶点
 ,它仅考虑 附近半径为
,它仅考虑 附近半径为  的球体,其中 表示距离当前顶点的最短路径,即 跳
的球体,其中 表示距离当前顶点的最短路径,即 跳hop。1跳表示直接邻居。
模型的整体架构如下图所示。其中:
1,2,3,4为图卷积的四个步骤。- 特征抽取层获取粗化图的多通道特征。
将卷积推广到图上需要考虑三个问题:
- 如何在图上涉及满足空间局部性的卷积核
- 如何执行图的粗化
graph coarsening,即:将相似顶点聚合在一起 - 如何执行池化操作
3.1.1 卷积核
给定输入
 ,其频域卷积为: ,其中
,其频域卷积为: ,其中  为卷积核:
为卷积核:其中
 为卷积核参数。
为卷积核参数。这种卷积有两个不足:
- 频域卷积在空域不满足空间局部性
- 卷积核参数数量为
我们可以通过多项式卷积核来克服这两个缺陷。令:

其中 为拉普拉斯矩阵
 的第 个特征值。即用特征值的
的第 个特征值。即用特征值的  次多项式来拟合卷积核参数。
次多项式来拟合卷积核参数。则有:
由于
 ,因此有 。
,因此有 。则卷积结果为:

现在的参数为 ,参数数量降低到
 。
。给定
Kronecker delta函数 ,其中:
即 的第
个分量为1,其余分量为0。则有:
输出的第
 个分量记作 ,令
个分量记作 ,令  的第 行第 列为 ,则有:
的第 行第 列为 ,则有:
可以证明:当 时,有
 ,其中 为顶点 和 之间的最短路径。
,其中 为顶点 和 之间的最短路径。因此当
 时,有 ,则有
时,有 ,则有  。即顶点 经过卷积之后,只能影响距离为 范围内的输出。
。即顶点 经过卷积之后,只能影响距离为 范围内的输出。因此 阶多项式实现的频域卷积满足
阶局部性,其卷积核大小和经典 CNN相同。切比雪夫多项式:
第一类切比雪夫多项式:
第二类切比雪夫多项式:

第一类切比雪夫多项式性质:
- 切比雪夫多项式
 是 次代数多项式,其最高次幂
是 次代数多项式,其最高次幂  的系数为
的系数为 - 当
 时,有
时,有 - 在 之间有
 个点 ,轮流取得最大值
个点 ,轮流取得最大值 1和最小值-1。 - 当
 为奇数时 为奇函数;当 为偶数时, 为偶函数
为奇数时 为奇函数;当 为偶数时, 为偶函数
- 切比雪夫多项式
切比雪夫逼近定理:在
 之间的所有首项系数为
之间的所有首项系数为1的一切 次多项式中, 对
对 0的偏差最小。即:其中
 为任意首项系数为
为任意首项系数为 1的 次多项式。定理:
- 令
 为定义域在 之间的连续函数的集合,
为定义域在 之间的连续函数的集合, 为所有的 次多项式的集合。如果
为所有的 次多项式的集合。如果  ,则 中存在一个
,则 中存在一个  的最佳切比雪夫逼近多项式。
的最佳切比雪夫逼近多项式。
- 令
推论:
- 如果 ,则 中存在唯一的、函数 的最佳切比雪夫逼近。
- 如果 ,则其最佳一致逼近 次多项式就是 在 上的某个 次拉格朗日插值多项式。
- 如果 ,则
注意到这里的卷积 计算复杂度仍然较高,因为这涉及到计算复杂度为
 的
的 矩阵-向量乘法运算。我们可以利用切比雪夫多项式来逼近卷积。
定义:
令
 ,其中 为
,其中 为  阶切比雪夫多项式, 为 阶切比雪夫多项式的系数。
阶切比雪夫多项式, 为 阶切比雪夫多项式的系数。根据切比雪夫多项式的性质我们有:
则卷积结果为:

由于有 以及
 为正交矩阵,因此有 ,其中
为正交矩阵,因此有 ,其中  。 考虑到 为
。 考虑到 为  的多项式,则有:
的多项式,则有:则有:

定义 ,则有:

最终有: 。其计算代价为
 。考虑到 为一个稀疏矩阵,则有
。考虑到 为一个稀疏矩阵,则有  。
。给定输入 ,其中
 为输入通道数。设 为输出通道数,则第
为输入通道数。设 为输出通道数,则第  个顶点的第 个输出通道为:
个顶点的第 个输出通道为:
其中 表示第
个输入通道, 为第 个顶点在输入通道 上的、对应于 的取值, 为
的取值, 为  的第 列,
的第 列, 为 矩阵的第 行。 为可训练的参数,参数数量为
为 矩阵的第 行。 为可训练的参数,参数数量为  。
。定义 为第
个输出通道对应于第 个输入通道的参数,则有:
以及:
其中
 为矩阵的第 行第 列, 为训练集损失函数,通常选择交叉熵损失函数。
为矩阵的第 行第 列, 为训练集损失函数,通常选择交叉熵损失函数。上述三个计算的复杂度为
 ,但是可以通过并行架构来提高计算效率。
,但是可以通过并行架构来提高计算效率。另外, 只需要被计算一次。
3.1.2 图粗化
池化操作需要在图上有意义的邻域上进行,从而将相似的顶点聚合在一起。因此,在多层网络中执行池化等价于保留图的局部结构的多尺度聚类。
但是图聚类是
NP难的,必须使用近似算法。这里我们仅考虑图的多层次聚类算法,在该算法中,每个层次都产生一个粗化的图,这个粗化图对应于图的不同分辨率。论文选择使用
Graclus层次聚类算法,该算法已被证明在图聚类上非常有效。每经过一层,我们将图的分辨率降低一倍。Graclus层次聚类算法:选择一个未标记的顶点
,并从其邻域内选择一个未标记的顶点 ,使得最大化局部归一化的割 cut 。
。然后标记顶点 为配对的粗化顶点,并且新的权重等于所有其它顶点和
 权重之和。
权重之和。持续配对,直到所有顶点都被探索。这其中可能存在部分独立顶点,它不和任何其它顶点配对。
这种粗化算法非常块,并且高层粗化的顶点大约是低一层顶点的一半。
3.1.3 池化
池化操作将被执行很多次,因此该操作必须高效。
图被粗化之后,输入图的顶点及其粗化后的顶点的排列损失是随机的,取决于粗化时顶点的遍历顺序。因此池化操作需要一个表格来存储所有的配对顶点,这将导致内存消耗,并且运行缓慢、难以并行实现。
可以将图的顶点及其粗化后的顶点按照固定的顺序排列,从而使得图的池化操作和经典的一维池化操作一样高效。这包含两步:
- 创建一颗平衡二叉树
- 重排列图的顶点或者粗化后的顶点
在图的粗化之后,每个粗化后的顶点要么有两个子结点(低层的两个配对顶点),要么只有一个子结点(低层该子结点未能配对)。
对于多层粗化图,从最高层到最底层,我们添加一批 “伪顶点” 添加到单个子结点的顶点,使得每个顶点都有两个子结点。同时每个“伪顶点”都有两个低层级的“伪顶点” 作为子结点。
- 这批“伪顶点”和其它任何顶点都没有连接,因此是“断开”的顶点。
- 添加假顶点人工增加了图的大小,从而增加计算成本。但是我们发现
Graclus算法得到的单子结点的顶点数量很少。 - 当使用
ReLU激活函数以及最大池化时,这批“伪顶点” 的输入为0。由于这些“伪顶点”是断开的,因此卷积操作不会影响这些初始的0值。
最终得到一颗平衡二叉树。
对于多层粗化图,我们在最粗粒度的图上任意排列粗化顶点,然后将其顺序扩散到低层图。假设粗化顶点编号为 ,则其子结点的编号为
 和 。因此这将导致低层顶点有序。
和 。因此这将导致低层顶点有序。池化这样一个重排列的图类似于一维池化,这使得池化操作非常高效。
由于内存访问是局部的,因此可以满足并行架构的需求。
一个池化的例子如下图。
图粗化过程:
 为原始图,包含
为原始图,包含8个顶点。深色链接表示配对,红色圆圈表示未能配对顶点,蓝色圆圈表示“伪顶点”一级粗化 :
二级粗化
 :
:G1顶点 G2顶点 备注2,3 14,5 20 0 未能配对
构建二叉树过程:
- 的
0顶点只有一个子结点,因此在 中添加一个“伪顶点”作为 的
中添加一个“伪顶点”作为 的 0顶点的另一个子结点。 - 的
3,5顶点只有一个子结点,因此在 中添加两个“伪顶点”作为 的 3,5顶点的另一个子结点。 - 的
1顶点是一个“伪顶点”,因此在 中添加两个“伪顶点”作为 的 1顶点的两个子结点。
- 的
重新编号:
- 将 的三个顶点依次编号为
0,1,2 - 根据 的规则为
 的十二个顶点依次编号为
的十二个顶点依次编号为 0,1,...,11
- 将
重排,重排结果见右图所示。
3.2 实验
我们将常规的
Graph CNN的卷积核称作Non-Param、增加平滑约束的样条插值卷积核称作Spline、Fast Graph CNN的卷积核称作Chebyshev。在这些图卷积神经网络中:
FCk表示一个带 个神经元的全连接层;Pk表示一个尺寸和步长为 的池化层(经典池化层或者图池化层);GCK表示一个输出 个feature map的图卷积层; 表示一个输出 个feature map的经典卷积层。- 所有的
FCk,Ck,GCk都使用ReLU激活函数。 - 所有图卷积神经网络模型的粗化算法统一为
Graclus算法而不是Graph CNN中的朴素聚合算法,因为我们的目标是比较卷积核而不是粗化算法。 - 所有神经网络模型的最后一层统一为
softmax输出层 - 所有神经网络模型采用交叉熵作为损失函数,并对全连接层的参数使用
 正则化
正则化 - 随机梯度下降的
mini-batch大小为100
MNIST实验:论文构建了
8层图神经网络,每张MNIST图片对应一个图Graph,图的顶点数量为978( ,再加上192个“伪顶点”);边的数量为3198。顶点
之间的边的权重为:其中
 表示顶点 的二维坐标。
表示顶点 的二维坐标。各模型的参数为:
标准卷积核的尺度为
5x5,图卷积核的 ,二者尺寸相同
,二者尺寸相同标准
CNN网络从TensorFlow MNIST教程而来,dropout = 0.5,正则化系数为 ,初始学习率为0.03,学习率衰减系数0.95,动量0.9。所有模型训练
20个epoch。
模型效果如下表所示,结果表明我们的
Graph CNN模型和经典CNN模型的性能非常接近。- 性能上的差异可以用频域卷积的各向同性来解释:一般图形中的边不具有方向性,但是
MNIST图片作为二维网格具有方向性,如像素的上下左右。这是优势还是劣势取决于具体的问题。 - 另外
Graph CNN模型也缺乏架构涉及经验,因此需要研究更适合的优化策略和初始化策略。

20NEWS实验:为验证
Graph CNN可以应用于非结构化数据,论文对20NEWS数据集应用图卷积来解决文本分类问题。20NEWS数据集包含18846篇文档,分为20个类别。我们将其中的11314篇文档用于训练、7532篇文档用于测试。我们首先抽取文档的特征:
- 从所有文档的
93953个单词中保留词频最高的一万个单词。 - 每篇文档使用词袋模型提取特征,并根据文档内单词的词频进行归一化。
论文构建了
16层图神经网络,每篇文档对应一个图Graph,图的顶点数量为一万、边的数量为132834。顶点 之间的权重为:
其中 为对应单词的
word2vec embedding向量。所有神经网络模型都使用
Adam优化器,初始学习率为0.001;GC32模型的 。结果如下图所示,虽然我们的模型未能超越
。结果如下图所示,虽然我们的模型未能超越Multinomial Naive Bayes模型,但是它超越了所有全连接神经网络模型,而这些全连接神经网络模型具有更多的参数。- 从所有文档的
我们在
MNIST数据集上比较了不同的图卷积神经网络架构的效果,其中包括:常规图卷积的 架构、增加平滑约束的样条插值Spline架构、Fast Graph CNN的Chebyshev架构,其中 。训练过程中,这几种架构的验证集准确率、训练集损失如下图所示,横轴表示迭代次数。
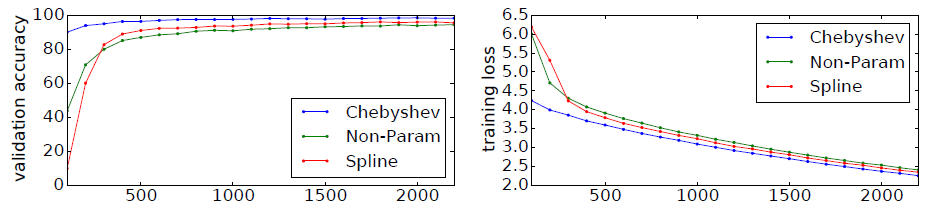
我们在
20NEWS数据集上比较了不同的图卷积神经网络架构的计算效率,其中 。我们评估了每个
mini-batch的处理时间,其中batch-size = 10。横轴为图的顶点数量 。可以看到 Fast Graph CNN的计算复杂度为 ,而传统图卷积(包括样条插值)的计算复杂度为 。我们在
MNIST数据集上验证了Fast Graph CNN的并行性。下面比较了经典卷积神经网络和Fast Graph CNN采用GPU时的加速比,其中batch-size = 100。可以看到我们的
Fast Graph CNN获得了与传统CNN相近的加速比,这证明我们提出的Fast Graph CNN有良好的并行性。我们的模型仅依赖于矩阵乘法,而矩阵乘法可以通过NVIDA的cuBLAS库高效的支持。
要想图卷积取得良好的效果,数据集必须满足一定条件:图数据必须满足局部性
locality、平稳性stationarity、组成性compositionality的统计假设。因此训练得到的卷积核的质量以及图卷积模型的分类能力很大程度上取决于数据集的质量。
从
MNIST实验我们可以看到:从欧式空间的网格数据中采用kNN构建的图,这些图数据质量很高。我们基于这些图数据采用图卷积几乎获得标准CNN的性能。并且我们发现,kNN中k的值对于图数据的质量影响不大。作为对比,我们从
MNIST中构建随机图,其中顶点之间的边是随机的。可以看到在随机图上,图卷积神经网络的准确率下降。在随机图中,数据结构发生丢失,因此卷积层提取的特征不再有意义。这表明图数据满足数据的统计假设的重要性。
在
20NEWS数据集构建图数据时,对于顶点 对应的单词,我们有三种表示单词的 的方法:- 将每个单词表示为一个
one-hot向量 - 通过
word2vec从数据集中学习每个单词的embedding向量 - 使用预训练的单词
word2vec embedding向量
不同的方式采用
GC32的分类准确率如下所示。其中:bag-of-words表示one-hot方法pre-learned表示预训练的embedding向量learned表示从数据集训练embedding向量approximate表示对learned得到的embedding向量进行最近邻搜索时,使用LSHForest近似算法。这是因为当图的顶点数量较大时,找出每个顶点的
kNN顶点的计算复杂度太大,需要一个近似算法。
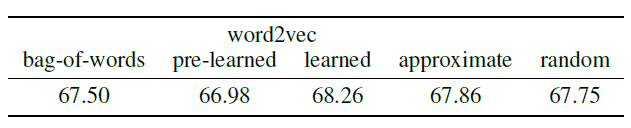
- 将每个单词表示为一个

