-
这里我们定义耦合异构网络为:两个不同类型但是相互关联的子网络组成的网络。这些子网络通过子网络之间的链接来相互连接。
例如:
- 论文引用网络中的 和
word:作者可以通过作者之间的交互来链接,单词可以通过单词共现来链接,作者可以通过他们文章的单词来链接。 - 社交网络中的
user和word:类似于论文引用网络中的author和word。 - 观影网络中的
customer和movie:观众可以通过观众之间的关系来链接,电影可以通过共同的演员或者导演来链接,观众可以通过他们观看的电影来链接。 - 基因和化合物:基因可以通过基因之间的相互作用来链接,化合物可以通过具有相同的基团关系来链接,基因可以通过
binding关系和化合物链接。
为直观说明这个概念,下图实现了
author和word网络的例子。其中作者通过co-authorship关系来链接,单词通过标题中的共现关系来链接。我们从DBLP数据集进行采样,采样的author包含2000 ~2003年在两个数据挖掘会议KDD,IDCM以及两个数据库会议SIGMOD,VLDB上发表论文的作者。author和word之间链接用黑线表示。为了更清晰的展示,我们忽略了author网络内部的边以及word网络内部的边,并且绘制的顶点大小和它的degree成正比。可以看到:
author形成了两个聚类,word也形成了两个聚类。这些聚类可以通过社团检测算法来生成。数据挖掘专家到数据挖掘领域单词之间的边,要比数据挖掘专家到数据库领域单词的边更多。
数据库专家到数据库领域单词之间的边,要比数据库专家到数据挖掘领域单词之变的边更多。
这说明:作者和单词之间的链接可以在存在作者之间链接的基础上,额外提供补充信息。这是因为相同领域的作者更有可能在其领域内的单词上存在链接,这使得仅仅从作者之间的链接学到的
embedding更加全面和准确。当作者之间缺乏链接时(如冷启动时),这种补充信息尤为重要。
学习单词的
embedding的情况也是类似的。 - 论文引用网络中的 和
目前存在一些分别作用于
author网络或者word网络的embedding方法,但是从单个网络的embedding方法扩展到用于耦合异构网络的embedding并不容易。主要挑战在于两个不同网络的异构性,这将导致两个异构的潜在空间latent space,而这两个空间的特征不能直接匹配。为解决该问题,论文
《Embedding of Embedding (EOE) : Joint Embedding for Coupled Heterogeneous Networks》提出了Embedding of Embedding : EOE方法,该方法通过引入一个调和嵌入矩阵harmonious embedding matrix从而将embedding从一个潜在空间进一步嵌入到另一个潜在空间。作为一种
embedding方法,EOE使得存在链接的顶点在潜在空间中尽可能接近。但是和现有embedding方法相比,EOE的关键区别在于:在EOE方法中存在两个子网络、三种类型的链接、两个潜在空间。此外EOE必须同时学习两个子网络的潜在特征,因为任一侧特征都可以通过网络间的链接向另一侧子网络提供补充信息。EOE模型存在三种类型的参数:两个子网络的embedding参数以及调和嵌入矩阵。为了优化目标函数,EOE提出了一种交替优化算法,其中每次仅针对其中某一种类型的参数进行优化。通过这种交替优化的方式,
EOE可以用一系列简单的优化代替对三种参数的比较困难的联合优化。DeepWalk的随机游走可能会更跨多个社区,这违背了保持网络结构的目标。
耦合异构网络:一个耦合异构网络是由通过网络间链接相连的两个不同、但是相关的子网络组成。“不同”指的是两个子网络的顶点是不同类型的,“相关” 指的是两个子网络的顶点存在某种联系。
定义两个子网络分别为:
 ,其中 分别表示两个子网络的顶点, ,
,其中 分别表示两个子网络的顶点, , 分别为两个子网络的边, 分别为两个子网络的边的权重。
分别为两个子网络的边, 分别为两个子网络的边的权重。定义耦合异构网络为:
 ,其中 为子网之间的边,
,其中 为子网之间的边, 为对应的权重。
为对应的权重。所有的边可以是带权重的、无权重的,有向的、无向的。
EOE假设存在链接的一对顶点在潜在空间中是相邻的。在子网络 中,设两个顶点
 的
的embedding向量分别为 ,则它们在潜在空间的相似度定义为:
在子网络 中,设两个顶点
 的
的embedding向量分别为 ,则它们在潜在空间的相似度定义为:
在异构网络 中,子网络
 的顶点 和子网络
的顶点 和子网络  的顶点 的相似度不能使用上式的定义,因为顶点
的顶点 的相似度不能使用上式的定义,因为顶点  的
的 embedding向量 和顶点 的
的 embedding向量 来自于不同的潜在空间。为了调和两个潜在空间的异构性,我们引入一个调和嵌入矩阵
 ,其中 和
,其中 和  分别为 和
分别为 和  的潜在特征的维度。这个调和嵌入矩阵将一个潜在空间进一步嵌入到另一个潜在空间。
的潜在特征的维度。这个调和嵌入矩阵将一个潜在空间进一步嵌入到另一个潜在空间。因此子网络 的顶点
和子网络 的顶点 的相似度定义为:
EOE模型不仅使得存在链接的顶点彼此相似,还使得不存在链接的顶点彼此不相似。后者同样重要,因为它将保留哪些顶点之间不大可能交互的信息,这也是网络结构信息的一部分。因此
EOE将这两个规则(存在链接的顶点彼此相似、不存在链接的顶点彼此不相似)转化为一个最优化问题:最大似然存在链接的顶点pair对,以及最小似然不存在链接的顶点pair对。最大似然存在链接的顶点
pair对,这一部分的损失函数为:
其中 为顶点
 之间的边的权重, 为自定义的损失函数。
之间的边的权重, 为自定义的损失函数。最小似然不存在链接的顶点
pair对,这一部分的损失函数为:
当网络规模太多时,在所有不存在链接的顶点
pair对之间计算损失函数是不现实的,因此我们对不存在边的顶点pair对进行采样。
通常损失函数 应该是单调递减的:概率越大损失越小,概率为
1时损失为零。且损失函数应该是凸的、连续可微函数,从而方便优化。通常我们采用负的对数似然,因此有:
对图 以及两个子图之间的链接都采用这种方式的损失函数,再结合
 正则化,则总的损失函数为:
正则化,则总的损失函数为:调和嵌入矩阵的
 正则化用于执行特征选择来调和两个潜在空间,因为这会引入稀疏性。
正则化用于执行特征选择来调和两个潜在空间,因为这会引入稀疏性。
最小化 是一个凸优化问题。根据定义有:

其中 为各自潜在空间的维度。

其中 为
 为第 行第
为第 行第  列, 定义为:
列, 定义为:
对于
 不可微的,但是考虑到 在实际中很少会刚好为 0,因此如果
不可微的,但是考虑到 在实际中很少会刚好为 0,因此如果  在梯度下降过程中会穿越零点,则我们将其设置为零。这称作
在梯度下降过程中会穿越零点,则我们将其设置为零。这称作 lazy update,因此将鼓励 成为稀疏矩阵。EOE提出了一种基于梯度的交替优化算法,其中损失函数每次优化一种类型的变量直至收敛。这种交替优化算法用一系列更容易的优化来代替对三个变量的联合的、困难的优化。所谓交替优化,即直到当前类型的变量收敛时才进行下一个类型的变量的优化。这是因为每个类型的变量都影响其它两个类型的变量。如果当前类型的变量未能够优化,则它可能会带来负面影响。
一个直观的例子,在优化
author和word耦合异构网络时,假设作者A和作者B存在链接、作者A和单词 存在链接、作者
存在链接、作者 B和单词 存在链接、单词 和单词 存在链接。我们首先优化word子网络、再优化author子网络:- 假设在切换到
author子网络之前,word网络没有优化好,导致两个共现的单词 在
在 word潜在空间中并没有相邻。 - 在切换到
author子网络之后,由于作者A和B之间存在链接,则二者在author潜在空间中应该时相邻的。但是由于单词 和单词 在
在 word潜在空间中是不相邻的,则导致作者A和 在author潜在空间中被分开。
- 假设在切换到
EOE交替优化算法:输出:顶点 的
embedding向量,调和嵌入矩阵
算法步骤:
随机初始化顶点 的
embedding参数,以及矩阵预训练顶点 ,循环迭代直到算法收敛。迭代步骤为:
- 对
 里的所有顶点计算梯度 ,其中
里的所有顶点计算梯度 ,其中  为仅仅考虑子图 的损失函数。
为仅仅考虑子图 的损失函数。 - 线性搜索找到学习率
 。
。 - 更新参数: ,其中
 为迭代次数。
为迭代次数。
- 对
预训练顶点 ,循环迭代直到算法收敛。迭代步骤为:
- 对 里的所有顶点计算梯度 ,其中
 为仅仅考虑子图 的损失函数。
为仅仅考虑子图 的损失函数。 - 线性搜索找到学习率
 。
。 - 更新参数: ,其中 为迭代次数。
- 对
循环直到收敛,迭代步骤为:
- 固定 和 的
embedding参数,利用梯度下降算法优化 - 固定 的
embedding参数和 ,利用梯度下降算法优化 的 embedding参数 - 固定 的
embedding参数和 , 利用梯度下降算法优化 的 embedding参数
- 固定 和
- 最终返回顶点
 的
的 embedding向量以及调和嵌入矩阵
在
EOE交替优化算法中,我们对 和 分别执行预训练来学习顶点 和 的潜在特征,这是为了缓解在优化一种类型的顶点时,另一种类型的顶点带来负面影响。在
EOE交替优化算法中,我们采用backtracking line search方法为每次迭代选择一个合适的学习率。EOE交替优化算法的收敛条件为:当前迭代和最近一次迭代之间的损失函数差距小于一个阈值,如1e-5。EOE交替优化算法的复杂度和计算顶点embedding梯度、计算调和矩阵梯度的复杂度成比例。这些梯度的计算复杂度都是 ,其中 为存在链接的顶点
,其中 为存在链接的顶点pair对的数量,因此总的算法复杂度为: ,其中 为迭代次数。
,其中 为迭代次数。因此
EOE交替优化算法可以在多项式时间内求解出结果,所以它也适合大型网络。
EOE方法适合各种类型的图(带权图、无权图,有向图、无向图),它仅仅保留一阶邻近度。基准模型:
谱聚类:使用归一化的拉普拉斯矩阵的
top d个特征向量作为embedding向量。DeepWalk:通过截断的随机游走和SGNS来学习顶点的embedding向量。由于
DeepWalk仅适用于未加权的边,因此所有边的权重设置为 1 。LINE:分别定义损失函数来保留一阶邻近度和二阶邻近度来求解一阶邻近度representation和二阶邻近度representation,然后将二者拼接一起作为representation。LINE有两个变体:LINE-1st仅保留一阶邻近度,LINE-2nd仅保留二阶邻近度。由于如何合理的结合LINE-1st和LINE-2nd尚不清楚,因此我们不和LINE(1st+2nd)进行比较。
10.3.1 可视化
数据集:
DBLP数据集:从四个研究研究领域中的热门会议中得到的论文网络数据,包含的会议为:数据库领域的SIGMOD,VLDB,ICDE,EDBT,PODS,数据挖掘领域的KDD,ICDM,SDM,PAKDD, 机器学习领域的ICML,NIPS,AAAI,IJCAI,ECML,信息检索领域的SIGIR,WSDM,WWW,CIKM,ECIR。我们选择了
2000到2009年发表的论文,过滤掉少于三位作者的论文,并过滤掉停用词,如where,how。过滤后的作者网络author network包含4941位作者、17372条链接,单词网络word network有6615个单词、78217条链接,作者网络到单词网络的链接有92899条。所有基准模型都分别为作者和单词学习
embedding,而EOE通过联合推断来学习这些embedding。所有方法学到的
embedding向量的维度均为128维,我们采用t-SNE将这些向量映射到二维空间,如下图所示。其中:绿色为数据库领域、浅蓝色为信息检索领域、深蓝色为数据挖掘领域、红色为机器学习领域。author子网络和word子网络应该显示四个聚类的混合,因为所选的四个研究领域密切相关。谱聚类的结果不符合预期,因为谱聚类的学习目标不是保留网络结构。
尽管
DeepWalk和LINE在某种程度上表现更好,但是它们无法同时展示四个不同的聚类。DeepWalk的问题可能在于:随机游走跨越了多个研究领域,结果导致来自不同领域的数据点被分布在一起。LINE也有类似的问题,因为作者可能具有来自不同领域的其它作者的链接。

10.3.2 链接预测
链接预测问题是指:通过顶点之间的相似性来预测顶点之间是否存在链接。我们实验了两种场景:未来链接预测
future link prediction、缺失链接预测missing link prediction。- 未来链接预测:两个顶点之间目前不存在链接,但是将来存在链接。
- 缺失链接预测:两个顶点之间本来存在链接,但是未被观测到。
数据集:
DBLP co-authorship数据集:从四个研究研究领域中的热门会议中得到的论文网络数据,包含的会议为:数据库领域的SIGMOD,VLDB,ICDE,EDBT,PODS,数据挖掘领域的KDD,ICDM,SDM,PAKDD, 机器学习领域的ICML,NIPS,AAAI,IJCAI,ECML,信息检索领域的SIGIR,WSDM,WWW,CIKM,ECIR。我们使用前述的相同的预处理策略:过滤掉少于三位作者的论文,并过滤掉停用词。
DBLP论文引用数据集:数据源同上所述,但是这里考虑的是论文引用关系,而不是作者的共同发表关系。我们采用2000~2009年的论文,过滤掉该时间段内未发表的参考文献,并且过滤掉词频小于5的单词。最终论文引文子网络包含
6904篇论文、19801个引用关系(链接),单词子网络包含8992个单词、118518条链接,论文和单词之间有 条链接。SLAP数据集:数据包含基因以及化合物之间的关系。基因子网络包含基因和基因之间的相互作用,化合物子网络包含化合物之间是否具有相同的化学基团,两个子网络之间包含基因和化合物之间的作用。最终化合物子网络有
883个顶点、70746个链接,基因子网络有2472个基因、4396条链接,基因和化合物之间存在1134条链接。BlogCatalog数据集:包含博客作者之间关系的数据集。我们选择四种热门类型(Art,Computers,Music,Photography艺术、计算机、引用、摄影)的用户,这包含5009个用户,用户之间存在28406条链接。我们基于这些用户的博客来构建单词子网络,词频小于 8 的单词被过滤掉。我们采用窗口大小为 5 的滑动窗口来生成单词共现关系。最终得到的单词子网络包含
9247个单词、915655条链接。用户和单词之间存在
350434条链接。
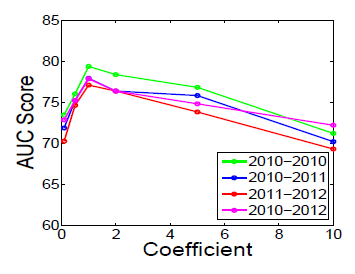
未来链接预测:我们采用
DBLP的2000到2009年发表的论文作为训练集,然后预测2010年、2010~2011年、2011~2012年、2010~2012年这四个时期的链接。在这四个时期,我们除了直接得到正样本(共同发表论文的作者) 之外,我们还通过计算来间接得到负样本:通过随机生成数量与正样本相同、没有共同发表论文的作者pair对。通过负样本来评估模型检测负样本的能力。我们通过以下概率来预测新的
co-authoreship相似性:其中
 为两个顶点的
为两个顶点的 embedding向量。我们使用
AUC来评估二类分类器的预测能力,结果如下。结果表明:- 所有的神经网络模型都优于谱聚类,这表明神经网络
embedding对于学习顶点潜在特征的有效性。 EOE方法在四个时间都优于其它模型,这表明EOE方法捕捉的信息更全面、准确。
为了研究
EOE性能优异的原因,我们研究这些方法如何针对测试样本进行预测。我们给出两个具有代表性的测试样本。这两个测试样本是发生在CVPR'10和SIGIR'10会议的两个co-authorship关系。- 所有的基准方法都低估这两个未来链接发生的概率。
EOE通过作者之间共享相似的研究方向的信息(通过common word给出)给出了最佳的预测。LINE(2nd)给出的预测结果被排除,因为它对所有测试样本(包括不存在co-authorship的作者pair对)预测的概率都接近100%。我们不知道原因,并且其背后的原因也不在本文讨论范围之内。但是我们知道LINE(2nd)的学习目标是保留二阶邻近度,而推断新的链接是预测一阶邻近度,二者不匹配。

- 所有的神经网络模型都优于谱聚类,这表明神经网络
缺失链接预测:我们在论文引用网络、社交网络、基因交互网络上执行缺失链接预测。我们开展了10次实验,分别对训练集中的链接保留比例从
0%~90%。其中,0%的保留比例即丢弃所有链接,这将导致冷启动问题。- 目前任何基准模型都无法解决冷启动问题,因为所有基准模型都依赖于已有的链接来学习潜在特征,而
EOE可以通过补充信息来解决冷启动问题。 - 在所有比例的情况下,
EOE仍然优于基准方法,这说明了EOE针对耦合异构网络共同学习embedding的优势。
- 目前任何基准模型都无法解决冷启动问题,因为所有基准模型都依赖于已有的链接来学习潜在特征,而
10.3.3 多类分类
多类分类任务需要预测每个样本的类别,其中类别取值有多个,每个样本仅属于其中的某一个类别。
数据集:
DBLP论文引用数据集:数据源同上所述,但是这里考虑的是论文引用关系,而不是作者的共同发表关系。我们采用2000~2009年的论文,过滤掉该时间段内未发表的参考文献,并且过滤掉词频小于5的单词。论文的标签是改论文所述的领域,为数据库、数据挖掘、机器学习、信息检索这四个领域之一。最终论文引文子网络包含
6904篇论文、19801个引用关系(链接),单词子网络包含8992个单词、118518条链接,论文和单词之间有59471条链接。我们开展了10次实验,分别对训练集中的链接保留比例从
10%~100%。一旦学到潜在特征,我们使用具有线性核的SVM来执行分类任务。我们采用
10-fold交叉验证的平均准确率作为评估指标,结果如下:EOE在所有比例的情况下,始终优于其它基准模型。- 当链接比例越少(如
10%~20%),EOE相比于基准模型的提升越明显。这是因为论文的摘要中包含了大量的关于论文研究领域的信息,EOE可以很好的利用这些信息。

10.3.4 多标签分类
多类分类任务需要预测每个样本的类别,其中类别取值有多个,每个样本可以属于多个类别。
数据集:
DBLP co-authorship数据集:从四个研究研究领域中的热门会议中得到的论文网络数据。每个作者有多个标签,因为一个作者可以是多个领域的专家。BlogCatalog数据集:包含博客作者之间关系的数据集。每个博客作者可以注册他们的博客为多个类别。
我们开展了5次实验,分别对训练集中的链接保留比例从
20%~100%。一旦学到潜在特征,我们使用具有线性核的二元分类SVM来执行多标签分类任务。我们采用
10-fold交叉验证的Micro-F1和Macro-F1作为评估指标,结果如下:EOE在所有任务中都超越了基准模型。- 当链接比例越少(如
20%),EOE相比于基准模型的提升越明显。
从可视化任务、链接预测任务、多类分类任务、多标签分类任务可以看到:多个子网络之间的链接提供的额外补充信息是有益的,因为它可以使得学到的潜在特征更加准确、全面,这在解决冷启动问题时尤为重要。
10.3.5 参数探索
EOE模型有两种主要的超参数:正则项的系数、潜在特征维度。在所有之前的实验中,这两个超参数都固定为常数,正则化系数设置为1.0,潜在特征维度为128。这里我们将正则化系数分别设置为
0.1,0.5,1.0,2.0,5.0,10.0、将潜在特征维度分别设置为32,64,128,256,512,然后观察这些超参数的影响。注意:研究潜在特征维度时,正则化系数固定为
1.0;研究正则化系数时,潜在特征维度固定为128。我们的训练数据集为DBLP co-authorship数据集。正则化系数:可以看到 对于正则化系数更为敏感,当正则化系数为
1.0时模型效果最好。