
-
目前已有一些方法,如
DeepWalk,LINE,PTE,node2vec,它们在实践中得到了有效的证明,但是背后的理论机制尚不了解。事实上在
Word Embedding任务中,带负采样的SkipGram模型已经被证明等价于一个word-context矩阵的隐式分解,但是还不清楚word-context矩阵和网络结构之间的关系。另外,尽管DeepWalk,LINE,PTE,node2vec之间看起来很相似,但是缺乏对其底层连接更深入的理解。论文
《Network Embedding as Matrix Factorization: Unifying DeepWalk, LINE, PTE, and node2vec》证明了DeepWalk,LINE,PTE,node2vec在理论上等价于隐式矩阵分解,并给出了每个模型的矩阵形式的闭式解。另外论文还发现:- 当上下文窗口大小 时,
LINE可以被视为是DeepWalk的特例。 PTE作为LINE的扩展,实际上它是多个网络联合矩阵的隐式分解。DeepWalk的隐式矩阵分解和图拉普拉斯算子之间存在理论联系,基于这种联系作者提出了一个新的算法NetMF来近似DeepWalk隐式矩阵分解的闭式解。
最后作者使用
SVD对每个算法的矩阵进行显式分解,通过实验证明了NetMF优于其它的几个模型。 - 当上下文窗口大小 时,
15.1.1 LINE
给定一个带权无向图
 ,
,LINE(2nd)任务是学到两个representation矩阵 :vertex represetation矩阵 :第 行 为顶点
行 为顶点  作为
作为vertex时的embedding向量。context representation矩阵 :第 行 为顶点 作为contex时的embedding向量。
LINE(2nd)的目标函数为:其中:
 为
为 sigmoid函数为负采样系数
 为用于产生负样本的
为用于产生负样本的 noise分布,在LINE原始论文中使用经验分布: ,其中 为顶点
为顶点 j的加权degree:
本文我们选择
 ,因为这种形式的经验分布将得到一个闭式解。定义 为所有顶点的加权
,因为这种形式的经验分布将得到一个闭式解。定义 为所有顶点的加权 degree之和,则有:
我们重写目标函数为:
我们在图
 的所有顶点上计算,从而得到期望为:
的所有顶点上计算,从而得到期望为:因此有:

则对于每一对顶点
(i,j),其局部目标函数local objective function为:定义
 ,根据
,根据 《NeuralWord Embedding as Implicit Matrix Factorization》的结论:对于一个足够大的embedding维度, 每个 之间可以认为是相对独立的。因此我们有:
为求解目标函数极大值,我们令偏导数为零,则有:
这个方程有两个闭式解:
 :其解为虚数,不予考虑。
:其解为虚数,不予考虑。- :有效解。
因此有:

定义对角矩阵 ,则
LINE(2nd)对应于矩阵分解:
.
15.1.2 PTE
PTE将文本网络分为三个子网络,假设单词集合为 ,文档集合为 ,标签集合为 :
,标签集合为 :word-word子网 :每个
:每个 word是一个顶点,边的权重为两个word在大小为T的窗口内共现的次数。假设其邻接矩阵为 ,定义
 为 第 行的元素之和, 定义 为
为 第 行的元素之和, 定义 为  第 列的元素之和。由于 为无向图,因此 为对称矩阵,所以有
第 列的元素之和。由于 为无向图,因此 为对称矩阵,所以有  。
。定义对角矩阵 ,
 ,它们分别由 的各行之和、各列之和组成。
,它们分别由 的各行之和、各列之和组成。word-document子网 :每个
:每个 word和document都是一个顶点,边的权重是word出现在文档中的次数。它是一个二部图,因此 不是对称矩阵,因此 。
。同样的我们定义对角矩阵 ,
 ,它们分别由 的各行之和、各列之和组成。
,它们分别由 的各行之和、各列之和组成。word-label子网 :每个
:每个 word和label都是一个顶点,边的权重为word出现在属于这个label的文档的篇数。它也是一个二部图,因此 不是对称矩阵,因此 。
。同样的我们定义对角矩阵 ,
 ,它们分别由 的各行之和、各列之和组成。
,它们分别由 的各行之和、各列之和组成。
PTE的损失函数为:
其中 分别为三个子网中的量,
 为三个超参数来平衡不同子网的损失, 为负采样系数。
为三个超参数来平衡不同子网的损失, 为负采样系数。根据前面的结论有:

令:
则有
 ,且有:
,且有:根据
PTE论文, 需要满足:这是因为
PTE在训练期间执行边采样,其中边是从三个子网中交替采样得到。
15.1.3 DeepWalk
DeepWalk首先通过在图上执行随机游走来产生一个corpus ,然后在 上训练
,然后在 上训练 SkipGram模型。这里我们重点讨论带负采样的SkipGram模型skipgram with negative sampling:SGNS。整体算法如下所示:输入:
- 图

- 窗口大小
- 随机游走序列长度

- 总的随机游走序列数量
- 图
输出:顶点的
embedding矩阵
算法步骤:
迭代: ,迭代过程为:
根据先验概率分布
 随机选择一个初始顶点 。
随机选择一个初始顶点 。在图
上从初始顶点 开始随机游走,采样得到一条长度为 的顶点序列 。统计顶点共现关系。对于窗口位置
 :
:考虑窗口内第 个顶点
 :
:- 添加
vertex-context顶点对 到 中。 - 添加
vertex-context顶点对 到 中。
- 添加
- 然后在 上执行负采样系数为
 的
的 SGNS。
根据论文
《NeuralWord Embedding as Implicit Matrix Factorization》,SGNS等价于隐式的矩阵分解:其中:
 为语料库大小; 为语料库
为语料库大小; 为语料库  中 共现的次数;
中 共现的次数; 为语料库中
为语料库中 vertex出现的总次数; 为语料库中
为语料库中 context出现的总次数; 为负采样系数。定理一:定义,则当 时有:

其中: 表述依概率收敛。
其物理意义为:
- 在所有正向转移过程中,
vertex-context 在语料库中出现的概率等于: 出现的概率,乘以从
在语料库中出现的概率等于: 出现的概率,乘以从  正向转移 步骤到达
正向转移 步骤到达  的概率。
的概率。 - 在所有正向转移过程中,
vertex-context在语料库中出现的概率等于: 出现的概率,乘以从 正向转移  步骤到达 的概率。
步骤到达 的概率。
证明:
首先介绍
S.N. Bernstein大数定律:设 为一个随机变量的序列,其中每个随机变量具有有限的期望 和有限的方差
为一个随机变量的序列,其中每个随机变量具有有限的期望 和有限的方差  ,并且协方差满足:当 时,
,并且协方差满足:当 时, 。则大数定律
。则大数定律 law of large numbers:LLN成立。我们观察到:
,
 。因此有:
。因此有:基于我们对图的假设和随机游走的假设,则有:
 发生的概率等于 的概率乘以 经过 步转移到 的概率。即:
发生的概率等于 的概率乘以 经过 步转移到 的概率。即:基于我们对图的假设和随机游走的假设,则有:当
 时有:
时有:其中:第一项为
 采样到 的概率;第二项为从 经过 步转移到 的概率;第三项为从 经过
采样到 的概率;第二项为从 经过 步转移到 的概率;第三项为从 经过  步转移到 得概率;第四项为从 经过 步转移到 的概率。
步转移到 得概率;第四项为从 经过 步转移到 的概率。
则有:
当
 时,从 经过
时,从 经过  步转移到 的概率收敛到它的平稳分布,即
步转移到 的概率收敛到它的平稳分布,即  。即:
。即:因此有
 。因此随机游走序列收敛到它的平稳分布。
。因此随机游走序列收敛到它的平稳分布。应用大数定律,则有:
类似地,我们有:

当 时,我们定义
 为事件 的指示器,同样可以证明相同的结论。
为事件 的指示器,同样可以证明相同的结论。- 在所有正向转移过程中,
事实上如果随机游走序列的初始顶点分布使用其它分布(如均匀分布),则可以证明:当
 时,有:
时,有:因此定理一仍然成立。
定理二:当
 时,有:
时,有:证明:
注意到
 ,应用定理一有:
,应用定理一有:进一步的,考察
的边际分布和 的边际分布,当  时,我们有:
时,我们有:定理三:在
DeepWalk中,当 时有:因此
DeepWalk等价于因子分解:
证明:
利用定理二和
continous mapping theorem,有:写成矩阵的形式为:

事实上我们发现,当 时,
DeepWalk就成为了LINE(2nd), 因此LINE(2nd)是DeepWalk的一个特例。
15.1.4 node2vec
node2vec是最近提出的graph embedding方法,其算法如下:输入:
- 图
- 窗口大小
- 随机游走序列长度
- 总的随机游走序列数量
- 图
输出:顶点
算法步骤:
构建转移概率张量

迭代: ,迭代过程为:
根据先验概率分布
 随机选择初始的两个顶点 。
随机选择初始的两个顶点 。在图
上从初始顶点 开始二阶随机游走,采样得到一条长度为 的顶点序列 。统计顶点共现关系。对于窗口位置
 :
:考虑窗口内第 个顶点
:- 添加三元组 到 中。
- 添加三元组 到 中。
- 添加三元组 到
- 然后在 上执行负采样系数为 的
SGNS。
注意:这里为了方便分析,我们使用三元组 ,而不是
vertex-context二元组。
node2vec的转移概率张量 采取如下的方式定义:
采取如下的方式定义:首先定义未归一化的概率:
其中
 表示在 的条件下,
表示在 的条件下, 的概率。
的概率。然后得到归一化的概率:
类似
DeepWalk,我们定义:
这里 为
previous顶点。定义
 为 出现在
为 出现在  中出现的次数;定义 为
中出现的次数;定义 为  出现在 中出现的次数。
出现在 中出现的次数。定义二阶随机游走序列的平稳分布为
 ,它满足: 。根据
,它满足: 。根据 Perron-Frobenius定理,这个平稳分布一定存在。为了便于讨论,我们定义每个随机游走序列的初始两个顶点服从平稳分布 。定义高阶转移概率矩阵 。
由于篇幅有限,这里给出
node2vec的主要结论,其证明过程类似DeepWalk:
因此
node2vec有:尽管实现了
node2vec的封闭形式,我们将其矩阵形式的公式留待以后研究。注意:存储和计算转移概率张量
 以及对应的平稳分布代价非常高,使得我们难以对完整的二阶随机游走动力学过程建模。但是最近的一些研究试图通过对 进行低秩分解来降低时间复杂度和空间复杂度:
以及对应的平稳分布代价非常高,使得我们难以对完整的二阶随机游走动力学过程建模。但是最近的一些研究试图通过对 进行低秩分解来降低时间复杂度和空间复杂度:
由于篇幅限制,我们这里主要集中在一阶随机游走框架
DeepWalk上。
15.1.5 NetMF
根据前面的分析我们将
LINE,PTE,DeepWalk,node2vec都统一到矩阵分解框架中。这里我们主要研究DeepWalk矩阵分解,因为它比LINE更通用、比node2vec计算效率更高。首先论文引用了四个额外的定理:
定理四:定义归一化的图拉普拉斯矩阵为 ,则它的特征值都是实数。
而且,假设它的特征值从大到小排列 ,则有:

进一步的,假设该图是连通图 (
connected),并且顶点数量 ,则有: 。
。证明参考:
Fan RK Chung. 1997. Spectral graph theory. Number 92. American Mathematical Soc.定理五:实对称矩阵的奇异值就是该矩阵特征值的绝对值。
证明参考:
Lloyd N Trefethen and David Bau III. 1997. Numerical linear algebra. Vol. 50. Siam.定理六:假设 为两个对称矩阵,假设将
 的奇异值按照降序排列,则对于任意 ,以下不等式成立:
的奇异值按照降序排列,则对于任意 ,以下不等式成立:
证明参考:
Roger A. Horn and Charles R. Johnson. 1991. Topics in Matrix Analysis. Cambridge University Press. https://doi.org/10.1017/CBO9780511840371
考察
DeepWalk的矩阵分解:忽略常量以及
element-wise的log函数,我们关注于矩阵: 。
。根据定理四,实对称矩阵 存在特征值分解
 ,其中 为正交矩阵、
,其中 为正交矩阵、  为特征值从大到小构成的对角矩阵。
为特征值从大到小构成的对角矩阵。根据定理三可知, ,并且
 。
。考虑到 ,因此有:

我们首先分析 的谱。显然,它具有特征值:

这可以视为对 的特征值
 进行一个映射 。这个映射可以视为一个滤波器,滤波器的效果如下图所示。可以看到:
进行一个映射 。这个映射可以视为一个滤波器,滤波器的效果如下图所示。可以看到:- 滤波器倾向于保留正的、大的特征值。
- 随着窗口大小
 的增加,这种偏好变得更加明显。
的增加,这种偏好变得更加明显。
即:随着 的增加,滤波器尝试通过保留较大的、正的特征值来近似低阶半正定矩阵。
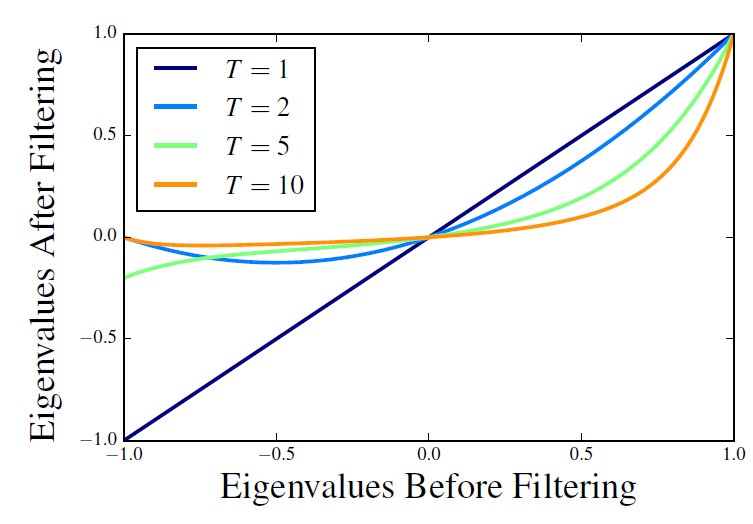
然后我们分析 的谱。
根据定理五,矩阵
 的奇异值可以根据其特征值的绝对值得到。我们将 进行降序排列,假设排列的顺序为
的奇异值可以根据其特征值的绝对值得到。我们将 进行降序排列,假设排列的顺序为  ,则有:
,则有:考虑到每个
 都是正数,因此我们可以将 的奇异值根据特征值
都是正数,因此我们可以将 的奇异值根据特征值  降序排列。假设排列的顺序为 ,则有:
降序排列。假设排列的顺序为 ,则有:
特别的, 为最小的
degree。通过应用两次定理五,我们可以发现第
 个奇异值满足:
个奇异值满足:因此
的第 个奇异值的上界为  。
。另外,根据瑞利商,我们有:
应用定理七,我们有:

为了说明过滤器 的效果,我们分析了
Cora数据集对应的引文网络。我们将引文链接视为无向边,并选择最大连通分量largest connected component。我们分别给出了
 、 以及
、 以及  按照降序排列的特征值,其中 。
按照降序排列的特征值,其中 。对于
,最大的特征值为 ,最小特征值为  。
。对于 ,我们发现:它的所有负特征值以及一些小的正特征值都被过滤掉了
filtered out。对于
,我们发现:- 它的奇异值(即特征值的绝对值)被 的奇异值所限制
bounded。 - 它的最小特征值的被
 的特征值所限制
的特征值所限制 bounded。
- 它的奇异值(即特征值的绝对值)被 的奇异值所限制
基于前面的理论分析,我们提出了一个矩阵分解框架
NetMF,它是对DeepWalk和LINE的改进。为表述方便,我们定义:

因此 对应于
DeepWalk的矩阵分解。对于很小的
,我们直接计算 并对  进行矩阵分解。
进行矩阵分解。考虑到直接对 进行矩阵分分解难度很大,有两个原因:
- 当
 时, 的行为未定义。
时, 的行为未定义。 - 是一个巨大的稠密矩阵,计算复杂度太高。
受到
Shifted PPMI启发,我们定义 。这使得 中每个元素都是有效的,并且 是稀疏矩阵。然后我们对 进行奇异值分解,并使用它的
中每个元素都是有效的,并且 是稀疏矩阵。然后我们对 进行奇异值分解,并使用它的 top奇异值和奇异向量来构造embedding向量。- 当
对于很大的
,直接计算 的代价太高。我们提出一个近似算法,主要思路是:根据  和归一化拉普拉斯算子之间的关系来近似 。
和归一化拉普拉斯算子之间的关系来近似 。首先我们对
 进行特征值分解,通过它的
进行特征值分解,通过它的 top个特征值和特征向量 来逼近 。
来逼近 。由于只有
top 个特征值被使用,并且涉及的矩阵是稀疏的,因此我们可以使用
个特征值被使用,并且涉及的矩阵是稀疏的,因此我们可以使用 Arnoldi方法来大大减少时间。然后我们通过 来逼近
。
算法:
输入:
- 图
- 窗口大小
输出:顶点的
embedding矩阵算法步骤:
如果
较小,则计算:如果
较大,则执行特征值分解: 。然后计算:
执行 维的
SVD分解: 或者 。
或者 。返回
 作为网络
作为网络 embedding。
对于较大的 ,可以证明
 逼近 的误差上界,也可以证明
逼近 的误差上界,也可以证明  逼近 的误差上界。
逼近 的误差上界。定理八:令
 为矩阵的
为矩阵的 Frobenius范数,则有:证明:
第一个不等式:可以通过
F范数的定义和前面的定理七来证明。第二个不等式:不失一般性我们假设
 ,则有:
,则有:第一步成立是因为: 对于
 有 ;第二步成立是因为:
有 ;第二步成立是因为: 。因此有 。
。因此有 。另外,根据
 和 的定义有:
和 的定义有:
因此有: 。
DeepWalk尝试通过随机游走来对顶点抽样,从而期待用经验分布来逼近真实的vertex-context分布。尽管大数定律可以保证这种方式的收敛性,但是实际上由于真实世界网络规模较大,而且实际随机游走的规模有限(随机游走序列的长度、序列的数量),因此经验分布和真实分布之间存在gap。这种gap会对DeepWalk的性能产生不利影响。NetMF通过直接建模真实的vertex-context分布,从而降低了这种gap,从而得到比DeepWalk更好的效果。
15.2 实验
作者在多标签顶点分类任务中评估
NetMF的性能。数据集:
BlogCatalog数据集:由博客作者提供的社交关系网络。标签代表作者提供的主题类别。Flickr数据集:Flickr网站用户之间的关系网络。标签代表用户的兴趣组,如“黑白照片”。Protein-Protein Interactions:PPI:该数据集包含蛋白质和蛋白质之间的关联,标签代表基因组。Wikipedia数据集:来自维基百科,包含了英文维基百科dump文件的前 个字节中的单词共现网络。顶点的标签表示通过
个字节中的单词共现网络。顶点的标签表示通过Stanford POS-Tagger推断出来的单词词性Part-of-Speech:POS。
Baseline模型:我们将NetMF(T=1)、NetMF(T=10)和LINE,DeepWalk进行比较。- 所有模型的
embedding维度都是128维。 - 对于
NetMF(T=10),我们在Flickr数据集上选择 ,在其它数据集上选择 。
。 - 对于
DeepWalk,我们选择窗口大小为10、随机游走序列长度40、每个顶点开始的随机游走序列数量为80。
我们重点将
NetMF(T=1)和DeepWalk进行比较,因为二者窗口大小都为1;重点将NetMF(T=10)和DeepWalk进行比较,因为二者窗口大小都为10。- 所有模型的
和
DeepWalk相同的实验步骤,我们首先训练整个网络的embedding,然后随机采样一部分标记样本来训练一个one-vs-rest逻辑回归分类模型,剩余的顶点作为测试集。我们评估测试集的Micro-F1指标和Macro-F1指标。为了确保实验结果可靠,每个配置我们都重复实验10次,并报告测试集指标的均值。对于
BlogCatalog,PPI,Wikipedia数据集,我们考察分类训练集占比10%~90%的情况下,各模型的性能;对于Flickr数据集,我们考察分类训练集占比1%~10%的情况下,各模型的性能。完成的实验结果如下图所示。可以看到:
NetMF(T=1)相对于LINE(2nd)取得了性能的提升,NetMF(T=10)相对于DeepWalk也取得了性能提升。- 在
Wikipedia数据集中,窗口更小的NetMF(T=1)和LINE(2nd)效果更好。这表明:短期依赖足以建模Wikipedia网络结构。
如下表所示,大多数情况下当标记数据稀疏时,
NetMF方法远远优于DeepWalk和 。- 在

